29.03.2012, 14:15 Uhr
Hadoop - der kleine Elefant für die grossen Daten
Big Data in den Griff zu bekommen dürfte in den kommenden Jahren eine der Kernaufgaben der IT sein. Mittlerweile bieten grosse und kleine Anbieter viele verschiedene Werkzeuge dafür an. Zentraler Bestandteil ist oft Hadoop.

Kleiner Elefant für große Daten - Hadoop.
Hadoop ist ein in Java programmiertes Software-Framework, mit dessen Hilfe Anwender rechenintensive Prozesse mit grossen Datenmengen auf Server-Clustern abarbeiten können. Applikationen können mit Hilfe von Hadoop komplexe Computing-Aufgaben auf tausende von Rechnerknoten verteilen und Datenvolumina im Petabyte-Bereich verarbeiten, so das Versprechen der Entwickler.
Wer hat Hadoop erfunden?
Angestossen wurde das Hadoop-Projekt von Doug Cutting. Als Google Ende 2004 Informationen über seinen MapReduce-Algorithmus veröffentlichte, mit dessen Hilfe sich komplexe Computing-Aufgaben relativ einfach zerlegen und innerhalb von Server-Clustern parallelisieren lassen, erkannte der Entwickler und Suchmaschinen-Spezialist die Bedeutung dieser Entwicklung und startete Hadoop. Cutting, der zuvor unter anderem bei Excite, Apple und in den renommierten Labors von Xerox Parc an Suchtechniken gearbeitet hatte, war zu dieser Zeit bei Yahoo beschäftigt. Bei dem Internet-Pionier trieb er im Folgenden die Hadoop-Entwicklung weiter voran und kümmerte sich auch um die Implementierung der neuen Technik in die Yahoo-Systeme. Heute ist Cutting bei Cloudera beschäftigt. Der Softwareanbieter offeriert eine auf Hadoop basierende Daten-Management-Plattform. Ausserdem fungiert der Entwickler seit September 2010 als Chairman der Apache Software Foundation (ASF), unter deren Dach derzeit die weitere Hadoop-Entwicklung gesteuert wird. Namensgeber für Hadoop war übrigens der Spielzeugelefant von Cuttings Sohn. Daher auch das Logo mit dem gelben Elefanten.
Wer entwickelt Hadoop?
Die Basis für Hadoop bildeten Entwicklungen bei grossen Internet-Konzernen wie Yahoo und Google. Diese Unternehmen standen von Beginn an vor der Herausforderung, grosse Datenmengen zügig bearbeiten zu müssen - eine Anforderung, mit der sich heute mehr und mehr Unternehmen konfrontiert sehen. Google beispielsweise hat schon vor beinahe zehn Jahren sein Google File System (GFS) und den Map-Reduce-Algorithmus entwickelt. Beide Komponenten bilden das Herzstück der internen IT des Suchmaschinenanbieters. Die eigenen Implementierungen haben die Google-Verantwortlichen der Community daher zwar nicht zur Verfügung gestellt, jedoch in den Jahren 2003 und 2004 technische Details ihrer Entwicklungen veröffentlicht. Entwickler haben dies aufgegriffen und wie beispielsweise Cutting mit Hadoop eigene Projekte gestartet. Seit Januar 2008 ist Hadoop ein Top-Level-Projekt der Apache Software Foundation (ASF). Ende 2011 hat das Software-Framework den Release-Status 1.0.0 erreicht.
Lesen Sie auf der nächsten Seite: Woraus besteht Hadoop?
Woraus besteht Hadoop?
Rund um das Hadoop-Framework gibt es eine Reihe verschiedener Projekte, die unter dem Dach der Apache Software Foundation vorangetrieben werden. Hadoop selbst setzt sich aus folgenden drei Komponenten zusammen:
- «Hadoop Common» bietet ein Toolset aus Grundfunktionen, das alle anderen Bausteine benötigen. Über eine Schnittstelle werden beispielsweise die Zugriffe auf die darunterliegenden File-Systeme gesteuert. Das Paket enthält auch die notwendigen Java-Archiv-(JAR-)Files und -Scripts, um Hadoop starten zu können. Ferner bietet Hadoop Common eine Schnittstelle für die Remote-Procedure-Call-(RPC-)Kommunikation innerhalb des Clusters sowie Bibliotheken für die Serialisierung von Daten. Ausserdem finden Anwender hier den Sourcecode, die Dokumentation sowie Informationen, welche weiteren Unterprojekte für Hadoop verfügbar sind.
- Das «Hadoop Distributed File System» (HDFS) stellt ein hochverfügbares und leistungsfähiges Dateisystem dar, mit dessen Hilfe Anwender grosse Datenmengen speichern können sollen. Das System unterstützt nach Angaben der Entwickler Systeme mit mehreren 100 Millionen Dateien.
- Hadoop enthält darüber hinaus eine Implementierung des von Google entwickelten MapReduce-Algorithmus. MapReduce bildet im Rahmen von Hadoop eine Art Software-Unter-Framework beziehungsweise Engine, die verschiedene Funktionen bereitstellt. Grundidee von Map-Reduce ist, Rechenaufgaben in kleine Teile zu zerlegen, auf eine Vielzahl von Rechnern zu verteilen (Map), dort extrem parallelisiert abzuarbeiten und die Ergebnisse wieder zusammenzuführen (Reduce).
Weitere Projekte bringen mehr Funktionen für Hadoop
Rund um Hadoop gibt es eine Reihe verschiedener Apache-Projekte, die verschiedene Zusatzfunktionen entwickeln und anbieten. Hier eine Auswahl:
- Avro hilft Anwendern, Daten zu strukturieren und sicher in Containern abzulegen.
- Cassandra ist eine verteilte NoSQL-Datenbank, die eine hohe Skalierbarkeit und Verfügbarkeit bieten soll. Die Software wurde von Facebook entwickelt und später an die Apache Software Foundation übergeben.
- Chukwa sammelt Daten und erlaubt Anwendern das Monitoring grosser verteilter Systeme.
- HBase ist eine hochskalierbare verteilte Datenbank für das Handling umfangreicher Tabellen, mit denen sich grosse Mengen strukturierter Daten verwalten lassen sollen.
- Hive ist ein Data Warehouse für Hadoop, das über eine SQL-ähnliche Syntax (HiveQL) Abfragen und Analysen ermöglicht.
- Mahout bietet Anwendern verschiedene Algorithmen für das Data Mining in grossen Datenbanken. Dabei lassen sich auch unstrukturierte Daten auswerten.
- Pig stellt eine Plattform für die Auswertung grosser Datenmengen zur Verfügung. Neben Analysewerkzeugen gibt es auch eine Infrastrukturebene, um das Tool anzupassen.
- ZooKeeper bietet Funktionen und Services, um verteilte Applikationen zu koordinieren.
Lesen Sie auf der nächsten Seite: Wie funktioniert Hadoop?
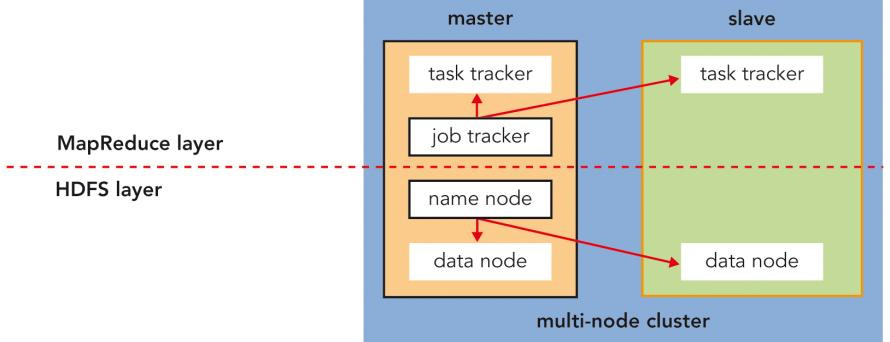
Wie funktioniert Hadoop?
Folgende zwei technischen Grundprinzipien bestimmen die grundlegende Funktionsweise von Hadoop:
- HDFS verteilt als Cluster-Datei-System die Daten auf verschiedene Systeme in einem Rechnerverbund.
- Mit MapReduce werden die Daten an ihrem Ablageort verarbeitet (Prinzip: Data Locality). Das beschleunigt die Rechenarbeit und verringert den Netzdurchsatz. Dafür teilt der Algorithmus die Datenverarbeitung in kleine Portionen auf und wickelt diese parallel ab.
Welche Systemvoraussetzungen benötigt Hadoop?
Hadoop-Cluster lassen sich, wie es auch die Spezifikationen des Google File System (GFS) vorsehen, mit Hilfe von Standardrechnern aufbauen. Da in einem solchen Rechnerverbund von Hardwareausfällen auszugehen ist, muss das Dateisystem auf Fehlertoleranz ausgelegt sein. Das funktioniert bei Hadoop wie oben beschrieben durch Replikation der Daten. Wie die Cluster-Hardware zu dimensionieren ist, hängt von der Komplexität der Rechenaufgaben sowie den zu verarbeitenden Datenmengen ab. Grundsätzlich gilt jedoch, dass der Master-Knoten in Bezug auf die Grösse des Arbeitsspeichers und die Prozessorleistung stärker dimensioniert werden muss als die Slave-Systeme. Für grosse Cluster bietet sich ein 64-Bit-System auf dem NameNode an, um mehr Arbeitsspeicher adressieren zu können. Das ist notwendig, um umfangreiche Datenstrukturen im Hauptspeicher vorzuhalten. Als Betriebssystem für die Knoten eines Hadoop-Clusters empfehlen Entwickler Linux. Darüber hinaus eignen sich auch verschiedene Unix-Derivate wie beispielsweise Solaris. Für den Hadoop-Betrieb ist ausserdem ein Java Developer Kit (JDK) ab Version 1.6 erforderlich. Entwickler raten den Nutzern, die offizielle Java-Distribution von Oracle/Sun zu nutzen.
Wer nutzt Hadoop?
Viele grosse Internet-Companies, die zum Teil auch an der Entwicklung des Software-Frameworks beteiligt waren, setzen Hadoop bereits ein, auch als Basis ihrer geschäftskritischen Systeme. Facebook nutzt das Hadoop-System zum Beispiel als Warehouse für Web-Analysen, als Speicher für die verteilte Datenbank sowie als Backup für die SQL-Datenbank. 2010 lagerten bereits über 20 Petabyte Daten im Hadoop-Cluster. Ein Jahr später waren es schon 30 Petabyte. Yahoo, das massgeblich an der Entwicklung von Hadoop beteiligt war und auch viel eigenen Code an die Apache-Foundation weitergereicht hat, begann 2008 mit einem 10.000 Rechenkerne umfassenden Cluster. Eigenen Angaben zufolge liess sich damit der Aufbau der «Webmap», eines Yahoo-internen Index aller bekannten Web-Seiten inklusive der damit verbundenen Metadaten, um den Faktor 33 beschleunigen. Ebay hat die Zahl seiner Server im Hadoop-Cluster innerhalb eines Jahres verfünffacht und betreibt derzeit über 2500 Rechenknoten in diesem System. Der Betrieb von Ebay hänge inzwischen auch von Hadoop ab, geben die Verantwortlichen des Online-Auktionshauses unumwunden zu. Lesen Sie auf der nächsten Seite: Welche Hadoop-Produkte gibt es?
Welche Lizenz für Hadoop?
Hadoop ist eine freie Software, die unter der seit Anfang 2004 gültigen Apache License 2.0 steht und von den Web-Seiten der Apache Software Foundation heruntergeladen werden kann. Die Lizenz besagt, dass Anwender die Software frei verwenden, modifizieren und verteilen dürfen. Wenn man die Software und eigene Ergänzungen weiter- verteilt, muss allerdings kenntlich sein, welche Software unter der Apache-Lizenz verwendet wurde. Änderungen des Quellcodes müssen nicht an den Lizenzgeber zurückgeschickt werden. Zudem ist erlaubt, unter der Apache-Lizenz verfügbare Software in eigenen Softwareprodukten zu verwenden. Diese eigenen Produkte müssen nicht unter einer Apache-Lizenz verfügbar sein.
Welche Hadoop-Produkte gibt es?
Hadoop kann man nicht kaufen. Vielmehr nutzen verschiedene Software- und Serviceanbieter das Framework im Rahmen ihrer eigenen Produkte und Dienstleis-tungen, darunter etliche namhafte IT-Hersteller. Amazon.com bietet beispielsweise in seiner Elastic Compute Cloud (EC2) mit «Elastic MapReduce» einen Hadoop-Cluster zur Miete aus der Cloud an. Der Online-Händler kombiniert seine Cloud-Offerte ausserdem mit dem eigenen Speicherdienst Simple Storage Service (S3). IBM hat die eigene Software «InfoSphere BigInsights», die in erster Linie für die Analyse unstrukturierter Daten ausgelegt ist, um Hadoop-Technik erweitert. Ausserdem soll sich die Software auch als Cloud-Dienst nutzen lassen. Die IBM-Verantwortlichen haben bereits weitere Software und Softwaredienste rund um Hadoop angekündigt. Oracle hat im Herbst vergangenen Jahres eine Big Data Appliance vorgestellt. Neben einer NoSQL-Datenbank und Linux als Betriebssystem soll in dem speziell auf die Verarbeitung grosser Datenmengen ausgelegten System auch Hadoop zum Einsatz kommen. Storage-Spezialist EMC, der seit einigen Jahren auch verstärkt Software entwickelt, unterstützt in seinen Isilon-NAS-Systemen seit Anfang des Jahres auch das Hadoop- Filesystem. Mit «Greenplum HD» bietet EMC darüber hinaus eine eigene Hadoop-Implementierung an, die sich aus dem kompletten Stack inklusive HDFS und Map-Reduce sowie diverser weiterer Apache-Projekte zusammensetzt. Microsoft will künftig den Hadoop-Einsatz für seine Cloud-Plattform Azure sowie den eigenen Windows Server unterstützen. In seinem Technet stellt der weltgrösste Softwarekonzern einschlägige Informationen für Entwickler bereit. Ausserdem wollen die Microsoft-Verantwortlichen in Sachen Hadoop mit der Firma Hortonworks kooperieren.In diese Ausgründung hat Yahoo Mitte vergangenen Jahres seine Hadoop-Entwicklung ausgelagert. Darüber hinaus soll es Hadoop-Konnektoren für Microsofts SQL-Datenbank und das Data Warehouse geben. Neben den grossen Anbietern existiert eine Reihe kleinerer Firmen, die sich auf Produkte und Services rund um Hadoop spezialisiert haben. Darunter findet sich beispielsweise Cloudera, wo Hadoop-Erfinder Cutting mittlerweile seine Brötchen verdient. Cloudera entwickelt neben einer eigenen Hadoop-Distribution Zusatzprodukte wie einen Desktop als Graphical User Interface (GUI), das die Administration von Hadoop-Clustern einfacher und komfortabler machen soll. * Dieser Artikel wurde ursprünglich in unserer Schwesterpublikation Computerwoche.de publiziert.





