03.09.2012, 10:40 Uhr
Big Data - BI der nächsten Generation
Unternehmen entdecken ihre strukturierten und unstrukturierten Daten als ungehobene Schätze. Big-Data-Techniken können helfen, an diese Assets heranzukommen. Doch der Weg ans Ziel ist weit - und der Ertrag unsicher.

Nur wer die richtigen Big-Data-Techniken einsetzt hat die Chance, die Daten auch richtig nutzen zu können.
Dieser Artikel wurde ursprünglich in unserer Schwesterpublikation Computerwoche.de veröffentlicht. Wahrscheinlich ist «Big Data» eines der IT-Trendthemen 2012, doch einen Konsens, was darunter zu verstehen ist, gibt es noch nicht. Grosse Datenmengen schnell und für komplexe Abfragen von immer mehr Nutzern bereitzustellen ist die eine Seite der Medaille. Die andere ist das Erschliessen von Datenquellen jenseits der strukturierten Daten, die ERP-, CRM- und andere operative Transaktionssysteme liefern. Hierbei handelt es sich vor allem um grosse Mengen maschinell erzeugter Daten. RFID-Funkchip-Erfassungen, Maschinendaten aus der Produktion (BDE), Logdaten der IT-Systeme, Sensordaten in Gebäuden oder der Umwelt, das World Wide Web mit Daten aus der eigenen Web-Präsenz oder dem eigenen Webshop zählen genauso dazu wie Social-Media-Daten aus Facebook, Twitter, Blogs oder Foren. Hinzu kommen unstrukturierte Daten wie Call-Center- oder Servicenotizen, Bilder auf Web-Seiten oder Videoclips, die als Basis für Analysen herangezogen werden können. Besonders herausfordernd sind die unterschiedlichen Strukturen dieser Daten, die typischerweise nicht in relationalen Datenbanken kosten- und verarbeitungseffizient gespeichert werden können.
Noch fehlen Erfahrungswerte
Unternehmen beginnen gerade zu untersuchen, welche Potenziale die Analyse solcher poly-strukturierten Daten birgt. Erste Erfolgsberichte zeigen die Möglichkeiten, klassische Herangehensweisen an Business Intelligence (BI) zu erweitern und auch aus diesen Daten Informationen herauszufiltern, die einen Wettbewerbsvorteil liefern. Spätestens wenn ein Wettbewerber die Kunden besser versteht oder seine Prozesse agil anpassen kann, läuten die Alarmglocken. Die Komplexität im Umgang mit diesen Daten kann allerdings hoch sein, und zur Bewertung von Qualität und Nutzen der Analyseergebnisse im Vergleich zum Aufwand fehlen häufig Erfahrungswerte. Insgesamt ist das Thema Big Data noch schwer greifbar, was sich auch in den unterschiedlichen Definitionen und Meinungen niederschlägt, die Marketing-gerecht zugeschnitten serviert werden. Einen breiten Konsens findet derzeit folgende Definition:
! KASTEN !
Der Nutzen von Big Data liegt vor allem in der Analyse grosser, erstmals zugänglichen Datenmengen, die mit den üblicherweise eingesetzten Techniken einer klassischen BI-Architektur aus Datenintegration, Datenspeicherung, Analytik und Visualisierung/Auswertung nicht richtig erreichbar sind. Die Verbindung der Analysen poly-strukturierter Daten mit der existierenden Welt der strukturierten Daten eröffnet weitreichende Potenziale und Chancen. Es entstehen neue und detaillierte Analysemöglichkeiten von Daten, die heute noch gar nicht oder nur teilweise genutzt werden können. Ausserdem werden die Analysesysteme flexibler, und mit Cloud Computing sind flexible Modelle für On-Demand-Analysen möglich. Voraussetzung, um das Big-Data-Versprechen einlösen zu können, sind neue Softwareprodukte, die verschiedene Anforderungen in vier Dimensionen erfüllen müssen:
- Grosse Datenvolumina müssen integriert, verarbeitet und gespeichert werden können (Dimension des Volumens);
- die zu verarbeitenden Daten sind poly-strukturiert (Dimension der Struktur);
- Datenquellen müssen schnell und flexibel integriert und analysiert werden können (Dimension Geschwindigkeit);
- Auswertung und Visualisierung der Inhalte sind schwieriger als im BI-Umfeld (Dimension der Analysekomplexität).
Insgesamt ergibt die Nutzung neuer Techniken, die für das Integrieren und Analysieren poly-strukturierter Daten entwickelt wurden, auch gute Möglichkeiten, die Kosten zu senken. Das liegt zum einen am Aufkommen bereits optimierter Lösungen, zum anderen an der teilweisen Verfügbarkeit von Open-Source-Lösungen. Lesen Sie auf der nächsten Seite: Wichtig ist der MapReduce-Ansatz
Wichtig ist der MapReduce-Ansatz
Wesentlicher Kern von Big-Data-Techniken ist der programmiergetriebene, datenzentrische Kern auf Basis des MapReduce-Ansatzes, dem Google zu Popularität verholfen hat. Die Idee dahinter ist simpel: Zerlege die Aufgabe in ihre kleinsten Teile, verteile diese zur massiv-parallelen Verarbeitung auf möglichst viele Rechner (map) und führe das Ergebnis wieder zusammen (reduce). Damit wird vor allem die Verarbeitung poly-strukturierter Daten ermöglicht, mit denen klassisch relationale Datenbanken, aber auch analytische Datenbanken in Data-Warehouse-Appliances oder massiv-parallele relationale Datenbanken ihre Probleme haben. Im Grunde genommen unterscheiden sich die Aufgaben aus Datenintegration und -speicherung, Analyse, Zugriff auf die Daten sowie Auswertung und Analyse nicht von denen einer klassischen BI-Architektur. Der grundlegende Unterschied zur klassischen BI ist die datenzentrische Ausrichtung auf Basis des MapReduce-Programmier-Frameworks, das eine hoch parallele Verarbeitung poly-strukturierter Daten ermöglicht. Der Markt für Big-Data-Software ist allerdings so vielschichtig wie die zu lösenden Aufgaben. Analog zu BI-, Data-Warehouse- oder Datenintegrations-Systemen gibt es auch im Big-Data-Bereich eine Vielzahl an alten und neuen Angeboten, die ähnliche Aufgaben wie die klassische BI zu lösen versprechen. Herausforderungen bestehen vor allem in der Integration von Big Data mit der klassischen BI, für die sich unterschiedliche architektonische und technische Ansätze anbieten. Aber auch in der Wahl der richtigen Software liegt ein Treiber, um die erhofften Vorteile in Ergebnis, Flexibilität und Kosten zu erhalten. Der BI-Markt wird nicht gerade überschaubarer, ganz im Gegenteil. Viele neue Anbieter oder Open-Source-Projekte positionieren sich im Markt für Big Data, die Grenzen zu traditioneller BI verschwimmen zusehends.
Datenintegration mit Sqoop & Co.
Auf der Ebene der Datenintegration steht die Geschwindigkeit und die Integration der heterogenen Datenquellen und -typen im Vordergrund. Zu beobachten ist die Integration von Big-Data-Funktionen in die etablierten Datenintegrations-Werkzeuge wie beispielsweise Informatica, Pentaho oder Pervasive. Big-Data-Funktionen umfassen hier Adapter in Hadoop-Dateisystemen wie dem Hadoop File System (HDFS) oder HIVE sowie auch die Integration mit dem MapReduce-Framework. Alternativen zur Einbindung von poly-strukturierten Datenquellen bieten Spezialisten wie Hadoop, Chukwa, Flume oder Sqoop. Lesen Sie auf der nächsten Seite: Siegeszug von Hadoop
Siegeszug von Hadoop
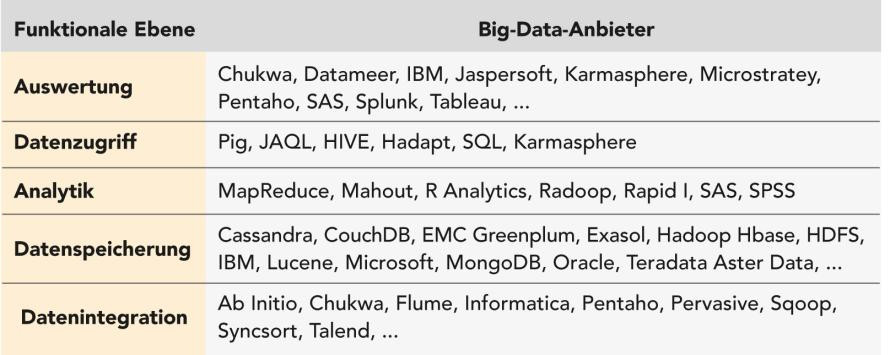
Neue BI-Werkzeuge
Die Analytik poly-strukturierter Daten wird einerseits stark getrieben durch die Modellbildung auf Basis von Detaildaten. Hier finden die sehr umfangreiche Open-Source-Bibliothek R, aber auch andere Data-Mining-Werkzeuge grossen Anklang. Andererseits existieren für die Big-Data-Welt auf der Auswertungsseite auch die klassischen BI-Anforderungen nach Dashboards und Berichten oder auch einfacheren Analyseumgebungen und die interaktive Datenexploration und Visualisierung für Fachanwender. Hier finden sich zahlreiche Spezialisten, die Lösungen für spezielle Anwendungsgebiete wie die Analyse von Weblogs, E-Commerce-Daten, Blogs, Twitter und Social-Media-Netzen anbieten. Ein Beispiel ist Splunk, das sich im Sinne der Operational BI auf das Aufbereiten von Logdaten von IT-Systemen konzentriert. Daneben kommen neue BI-Werkzeuge wie Datameer in den Markt, die den Fachanwender beim Integrieren, Speichern und Auswerten von Daten in Hadoop unterstützen. Ferner fangen auch klassische BI-Anbieter an, zum Beispiel über HIVE einen ergänzenden Zugriff auf neue Datenquellen zu schaffen. Die kleinen und wendigen Anbieter wie Tableau, Pentaho oder Jaspersoft sind die ersten im Markt. Die grossen Anbieter werden höchstwahrscheinlich bald folgen - wie immer teils durch Eigenentwicklung und teils durch Zukauf. Lesen Sie auf der nächsten Seite: Technik ist erschwinglich
Technik ist erschwinglich
Big Data ist in erster Linie ein Marketing-Begriff, der Methoden und Techniken umfasst, mit denen sich Datenvolumen, Komplexität, Geschwindigkeit und neue Analytik beherrschen lassen sollen, bei denen dies mit klassischen BI-Techniken nicht mehr sinnvoll möglich ist. Die Technik dafür ist durchaus erschwinglich. Open-Source-Lösungen und attraktive Angebote in der Cloud ermöglichen die Nutzung der notwendigen Werkzeuge und geben tiefen Einblick in die Daten. Teilweise erlauben sie es, Big Data mit eigenen Daten zu testen. Um poly-strukturierte Daten sinnvoll zu verarbeiten und wertvolle Ergebnisse daraus abzuleiten, müssen allerdings «Data Scientists» gefunden oder ausgebildet werden, die schon heute knapp sind. Am Softwaremarkt zeigen sich rund um Big Data viele Strömungen. Im Open-Source-Bereich steht vor allem Apaches Hadoop- Framework mit vielen ergänzenden Werkzeugen im Fokus der Aufmerksamkeit. Wie bei anderen Open-Source-Projekten auch entwickeln sich langsam Distributoren, die Bündelung und Support übernehmen und den Aufwand sowie das Risiko für Anwenderunternehmen reduzieren. Inzwischen setzen alle grossen Anbieter zum Speichern und Verarbeiten poly-strukturierter Daten auf Hadoop - mit eigenen Distributionen oder mit Partnerschaften. Etablierte BI- und Datenintegrations-Anbieter schaffen eine Integration mit Big-Data-Frameworks und Datenspeicherkomponenten. Wie im Softwaremarkt üblich, wird es je nach der Nachfrage zu einer Konsolidierungswelle kommen. Neben der Auswahl von Lösungen ist es für Unternehmen wichtig, die Integration von geplanten Big-Data-Anwendungen in die bestehende analytische Infrastruktur zu konzipieren.
Vorteile kombinieren
Ergebnisse der Analysen von grossen Mengen poly-strukturierter Daten sind häufig Kennzahlen oder andere strukturierte Informationen, die Unternehmen im Data Warehouse weiterverarbeiten möchten. Umgekehrt sind die qualitätsgesicherten Kennzahlen der Data-Warehouse-Welt interessante ergänzende Informationen, die bei der Analyse poly-strukturierter Daten hinzugezogen werden sollten. Werden beispielsweise riesige Mengen von Web-Logdaten zur Steuerung von Angeboten auf der Website genutzt, ist es sehr interessant, die Daten über das Verhalten eines Kunden auf der Website, die im Big-Data-Framework liegen, mit den Daten zu seinem früheren Kaufverhalten zu verbinden, die im Data Warehouse aufbewahrt sind. Lesen Sie auf der nächsten Seite: Wesentliche Herausforderungen für Big Data
Information Governance
Der Markt für Big-Data-Software ist jung, und die Anwendungsgebiete in Unternehmen werden noch sondiert und pilotiert. Unternehmen sollten die neuen Möglichkeiten von Big Data evaluieren. Sinnvoll ist es gleichzeitig, eine Information Governance zu einzuführen und vor allem zu leben. Das trägt entscheidend dazu bei, eine hohe Abfrage-Performance, eine gute Datenqualität und nicht zuletzt ein agiles BI-System zu erhalten. Am Ende ist das die Basis, um neue Ideen in der Peta- und Zettabyte-Welt umzusetzen.
Wesentliche Herausforderungen für Big Data
- Geschäftsfälle zu identifizieren, die eine Big-Data-Initiative zweifelsfrei rechtfertigen, fällt derzeit noch schwer. Qualität und Nutzen der Analyseergebnisse sind oft kaum absehbar und quantifizierbar, auch aufgrund fehlender Erfahrungswerte am Markt.
- Die Grenze zwischen Big-Data- und traditionellen BI- und Data-Warehouse-Szenarien ist fliessend. Anwender sollten prüfen, was sie mit ihrer verfügbaren Infrastruktur und zu den gegenwärtigen Kosten erreichen können. Neuinvestitionen sind nicht immer nötig.
- Eine Big-Data-Strategie kann als Erweiterung des BI-Fahrplans oder aber als völlig neue Aufstellung des Unternehmens definiert werden. Letzteres kann sinnvoll sein, wenn rund um den Produktionsfaktor Daten neue Wettbewerbsvorteile realisiert werden sollen.
- Sollen poly-strukturierte Daten integriert und verarbeitet werden, gilt es, das Verfahren mit der klassischen Analytik strukturierter Daten zu kombinieren. Ein Datenaustausch muss konzeptionell, architektonisch und technisch realisiert werden.
- Auf dem Arbeitsmarkt fehlt es an geeigneten Big-Data-Entwicklern und -Analysten. Gesucht werden neue Profile mit Programmier-Know-how und mathematisch-analytischen Fähigkeiten. Im englischen Sprachraum etabliert sich hierfür gerade das Berufsprofil des «Data Scientist». Hauptaufgaben auf der technischen Seite sind die Integration und Analyse der poly-strukturierten Daten unter anderem durch die Anwendung von MapReduce-Programmier-Frameworks. Nicht zu unterschätzen ist auch die Visualisierung der «Massen»-Daten, für die Darstellungsformen der klassischen BI-Welt nicht geeignet sind.
- Datenschutz und Ethik sind in Deutschland ein heisses Thema. Die Abgrenzung zwischen dem, was erlaubt ist und was nicht, ist unscharf und muss rechtlich geprüft werden. Vor allem Auswertungen personenbezogener Daten aus sozialen Netzwerken sind riskant.
- Die Auswahl passender Technologien für das Einbinden neuer Datenquellen, das Transformieren und Integrieren nach Regeln, das Speichern der Daten, das Laden der Analyseergebnisse und das Analysieren und Visualisieren ist eine Herausforderung. Das Lösungsangebot am Markt ist gross, und die Einsatzgebiete der unterschiedlichen Technologien sind nicht immer sofort ersichtlich.
- Skalierbarkeit, Performance, Realtime-Bereitstellung und Wartbarkeit sind wie in klassischen BI-Szenarien auch bei Big Data nicht so einfach zu gewährleisten. Fehlende Reife von Lösungsangeboten und knappes Know-how am Markt verschärfen die Situation.





