Wie funktioniert Fog Computing, und unter welchen Umständen empfiehlt sich das Konzept? Dieser Beitrag lichtet den Nebel.
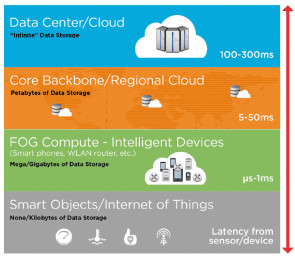
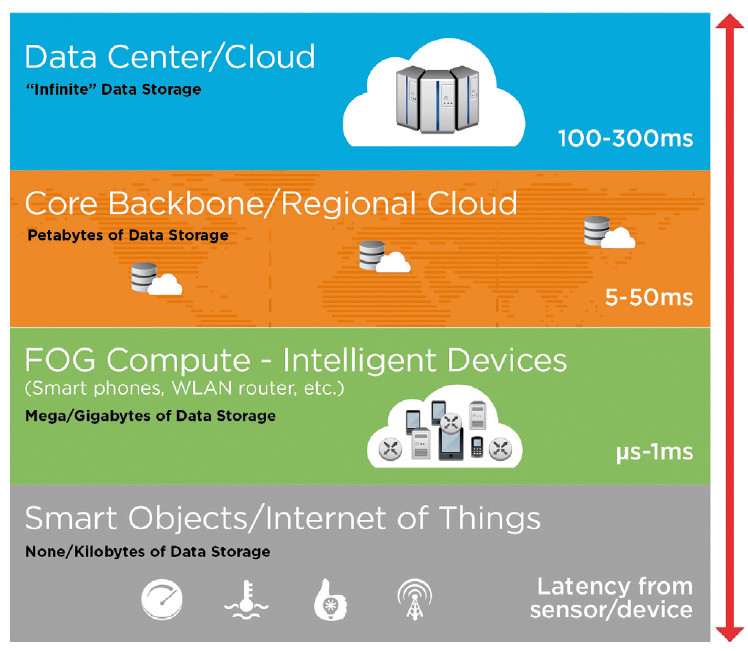
Der Unterschied zwischen Wolken und Nebel? Nebel tritt in Bodennähe auf, Wolken schweben weit entfernt am Himmel. Analog zu Cloud Computing hat Cisco bereits 2013 den Begriff Fog Computing geprägt. Damit ist aber nicht bloss gemeint, dass Verarbeitungsressourcen lokal platziert sind – das gibt es schon länger. Vielmehr definiert sich Fog Computing durch seine Fähigkeit zu hybriden Verarbeitungs- und Analytikprozessen, die lokale, standortnahe, zentrale Kapazitäten ebenso einschliessen können wie Cloud-Ressourcen. Mit Fog Computing rücken Daten- und Rechenressourcen näher zusammen. Digital erfasste und gespeicherte Informationen werden nicht mehr vollständig im Rechenzentrum oder in der Cloud verarbeitet, sondern grundlegende Verarbeitungsschritte finden bereits an ihrem Entstehungsort beziehungsweise in dessen unmittelbarer Nähe statt. So lassen sich Effizienz-, Leistungs-, Sicherheits- und Kostenvorteile realisieren. Allerdings ist hierfür eine Standort- und Netzwerkarchitektur notwendig, die sich von traditionellen Infrastrukturen unterscheidet. Fog Computing tritt nicht in Konkurrenz zur Cloud, sondern ist vielmehr eine Weiterentwicklung.
Gründe für Fog Computing
In den meisten Unternehmen sind Workloads, Daten und Anwendungen zentral in Rechenzentren und mittlerweile auch in der Cloud platziert, wobei unterschiedliche Clients an diversen Standorten darauf zugreifen. Alle massgeblichen Rechenfunktionen erfolgen also im Datacenter oder in der Cloud, die Clients initiieren nur die notwendigen Datentransfers über das Netzwerk und erhalten die Ergebnisse zurück. Diese Architektur hat den Vorteil, dass es einfach ist, die Applikationen und die Zugriffe zu managen sowie die Server- und Netzwerkauslastung zu optimieren. Allerdings führen Trends wie das Internet der Dinge dazu, dass immer umfangreichere Datenvolumina an sehr vielen, geografisch verteilten Endpunkten entstehen. Um diese zu sammeln, zu verarbeiten und zu analysieren, ist es häufig ineffektiv, die gesamten Daten über das Netzwerk zu den zentralen Verarbeitungsstandorten zu transferieren. Die Netzwerkkosten steigen, mit jedem Netzwerk-Hop sinkt das Sicherheitsniveau, zudem summieren sich die Latenzen. Ein logischer Schritt ist daher, die Verarbeitungsintelligenz näher an die Endpunkte zu rücken, an denen die Daten entstehen. Im Idealfall erfolgen die grundlegende Verarbeitung und eine Konsolidierung schon direkt am Sensor, der die Daten erzeugt. Meist ist es jedoch praktikabel, Daten in nahe bei den Endpunkten gelegenen Standorten oder Clouds zu verarbeiten. In beiden Fällen werden anschliessend nur relevante Daten an die zentralen entfernten Verarbeitungsressourcen im Rechenzentrum und vor allem in der Cloud übertragen.
Nächste Seite: Wo sich der Einsatz anbietet
Wo sich der Einsatz anbietet
Fog Computing empfiehlt sich oft, wenn die Datenquellen zwar verteilt sind, aber geografisch so dicht beieinanderliegen, dass eine lokale Abdeckung einfach zu erreichen ist. Da diese Daten häufig auch Auslöser für zeitsensitive lokale Aktionen sind, wird durch das Fog Computing auch die Servicequalität verbessert. Der Grund dafür sind geringere Latenzen.
Ein Argument für Fog Computing sind die stetig wachsenden Datenvolumina. Wenn diese bei Langstreckenübertragungen die verfügbaren Netzwerkressourcen und Bandbreiten überfordern, gilt es, soweit überhaupt möglich, entweder mit hohem Aufwand Netzwerke und/oder Bandbreiten auszubauen oder aber die Menge der übertragenen Daten zu reduzieren. Letzteres hat den Vorteil, dass dabei auch andere typische Problemstellen heutiger IT-Infrastrukturen angegangen werden. Folgendes Beispiel zeigt, wann eine Fog-Konfiguration als bessere Alternative zu einer direkten Verbindung in die Cloud fungieren kann: Ein System zur Verkehrsüberwachung sammelt an Hunderten von Standorten grosse Datenmengen in unterschiedlichen Formaten von diversen Gerätetypen wie Videokameras, strassenbasierten Sensoren und intelligenten Autos. Sollen die Daten zu Verkehrsspitzenzeiten, zu Ferienbeginn oder etwa bei Veranstaltungen in Gänze direkt in die Cloud transferiert werden, können örtlich Netzwerküberlastungen auftreten. Werden die Daten dagegen an Ballungsstandorten gesammelt, konsolidiert und ersten lokal relevanten Analysen unterzogen, stehen Informationen früher zur Verfügung und es müssen deutlich weniger Daten zur überregionalen Analytik in die zentrale Cloud-Anwendung gesendet werden. Nächste Seite: Fog ist ein Framework
Fog ist ein Framework
Für die Konfiguration einer Fog-Infrastruktur werden am Netzwerkrand installierte Hardware- und Software-Systeme sowie entsprechende Netzwerkverbindungen benötigt. Jeder Fog-Knoten muss über folgende Features verfügen:
Netzwerkkonnektivität
Prozessorkapazitäten, die ausreichen, um Anwendungen für Analytik und Filterung auszuführen
Speicherkapazitäten für die temporäre Erfassung und Aggregation von Daten
Sicherheitsfunktionen
Management- und Analyseplattformen
Die Gesamtheit aus Clients, Fog-Knoten mit Hard- und Software, Verbindungen sowie den zentralen Rechenzentrums- beziehungsweise Cloud-Applikationen verdeutlicht, dass Fog kein Produkt ist, sondern ein Framework. Entsprechend komplex können die Voraussetzungen für Anwender sein, die Fog Computing selbstständig realisieren und einsetzen wollen. Die Herausforderungen entstehen in unterschiedlichen Bereichen. So ist für viele Unternehmen die Finanzierung ein Hinderungsgrund. Denn im Gegensatz zum über die Betriebskosten abgerechneten Cloud Computing benötigen Fog-Systeme Investitionen in entsprechende Hardware für die Fog-Knoten. Auch bei der für eine schnelle Anpassung an Arbeits- und Marktbedingungen notwendigen Skalierbarkeit können Nachteile entstehen, die sich finanziell auswirken. Wie alle Hardware-basierten Technologien lassen sich Fog-Knoten nicht einfach und schnell skalieren, was oft zu Überkapazitäten führt. Weiterhin verursachen die Fog-Knoten allein schon aufgrund ihrer geografischen Verteilung umfangreiche Bereitstellungs- und Wartungsressourcen. * Roger Semprini ist Managing Director bei Equinix Schweiz de.equinix.ch