In-Memory-Datenbanken können riesige Terabyte-Datenbestände in Echtzeit analysieren. CEOs fällen Entscheide schneller, besser, treffsicherer. SAP-Co-Gründer Hasso Plattner erklärt, wie Schweizer mit In-Memory der Konkurrenz ein Schnippchen schlagen.
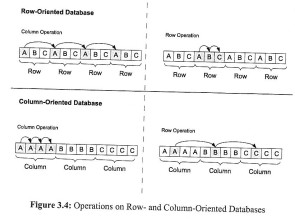
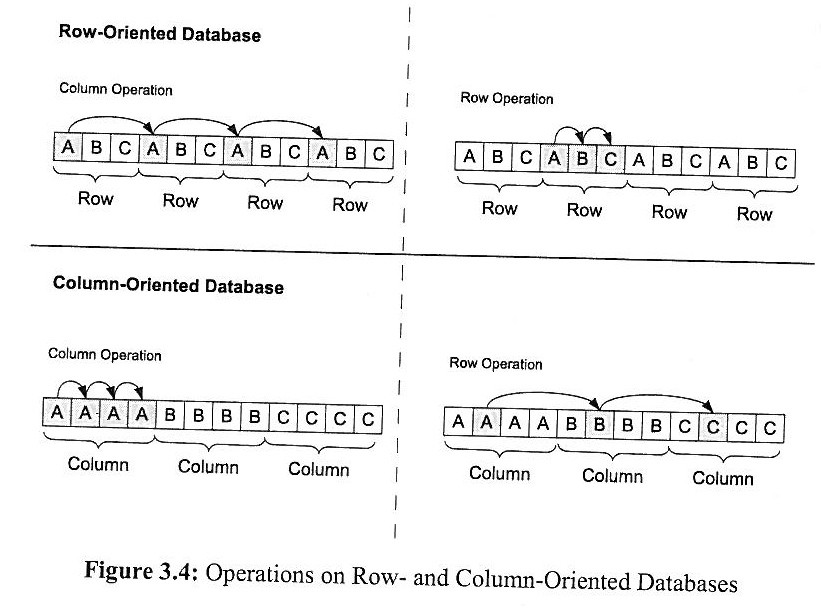
Konkurrierende Speicherstrategien: kolumnen- und zeilenorientierte Datenbankensysteme
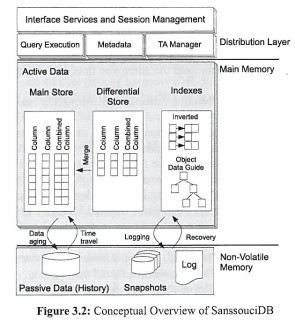
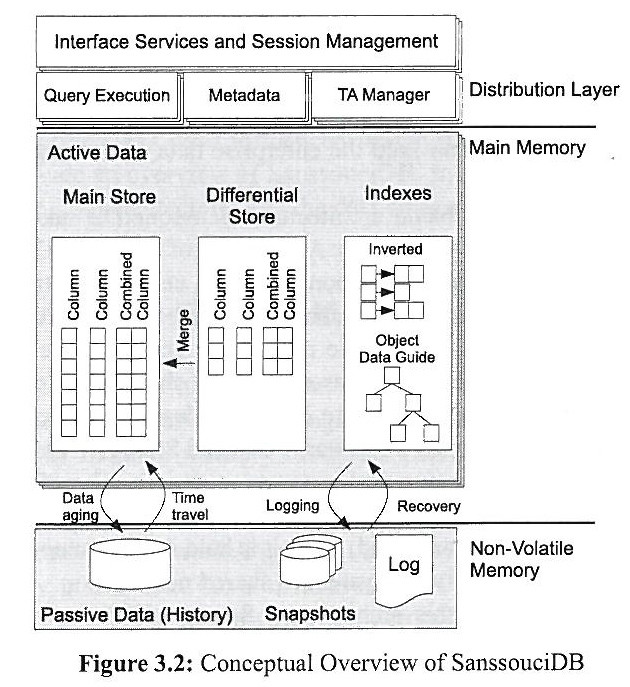
Relationale Datenbanksysteme (RDBMS) glänzen bei transaktionalen Standard-Aufgaben. Will ein Vertriebsmitarbeiter zum Beispiel eine Bestellung aufrufen, ist das kein Problem. Für superschnelle Analysen in Echtzeit aber - etwa die Gesamtumsätze einer Verkaufsregion, aufgeschlüsselt nach Wochentag und Verkäufer - sind sie nicht sonderlich gut geeignet. Sogenannte In-Memory-Datenbanken (IMDB), die stark vereinfacht das gesamte Datenvolumen in den Arbeitsspeicher laden, versprechen hier, wahre Performance-Wunder zu vollbringen. Und zwar für jede mögliche Abfrage, im Gegensatz zu den nur für bestimmte Abfrage-Sets optimierten OLAP-Würfeln (Online Analytical Processing). Eins ist klar: Superschnelle Entscheide setzen superschnellen Analysen voraus. SAP will mit seiner In-Memory-Appliance HANA sogar in die Zukunft schauen und die Abverkäufe grosser Discounter für die nächsten Monate prognostizieren, basierend auf allen Einzelverkäufen des abgelaufenen Geschäftsjahres, plus wirtschaftlicher Rahmenbedingungen und weiterer Parameter. Ist das möglich, können Schweizer Unternehmer der internationalen Konkurrenz mit In-Memory-Technologie ein Schnippchen schlagen? Was kann ein IMDB, und woran beisst es sich die Zähne aus? So funktioniert HANA SAP Co-Gründer Hasso Plattner liess erstmals die Katze aus dem Sack und gewährte tiefe Einblicke in die technischen Details seines In-Memory-Prototypen SanssouciDB, der auch in der "In-Memory Analytical Appliance" HANA am Werk ist. Performance-Vorteil 1: In-Memory-Datenbanken arbeiten kolumnenorientiert. Geht es etwa um Umsatzanalysen, lädt ein IMDB die Umsatzkolumne (resp. Datenbank-Spalte)und geht einfach seriell die Einzelvolumina nacheinander durch. Ein altes RDBMS dagegen lädt ganze Datensätze - also Datenreihen aus Kundeninformationen, Auftragsdetails und -volumina - und schleppt dadurch viel unnötigen Ballast mit, der für die Analyse gar nicht relevant ist, sondern lediglich die Pipelines verstopft und die Auswertung in die Länge zieht. Performance-Vorteil 2: SAPs IMDB Sanssouci, die in der Analytic Appliance HANA werkelt, nutzt optimal die Performance-Möglichkeiten moderner Mehrkernprozessoren aus. Stichwort Parallelverarbeitung: Die Walldorfer haben Scans (Suchläufe), Aggregationen (Gruppierungen von Kolumnen mithilfe von Hash-Tabellen) und Table Joins in Sanscoucci parallelisiert, und greifen dazu tief ins Innenleben der Prozessorkerne ein.
SAPs In-Memory-DB nutzt zum Beispiel sogenannte SIMD-Prozessorbefehle (single instruction, multiple data), die eine Operation über unterschiedliche Daten-Sets gleichzeitig, praktisch auf einen Streich, ausführen. Stark vereinfacht kommt es darauf an, Daten, die mit hoher Wahrscheinlichkeit für die gerade laufende Analyse als nächstes benötigt werden, in einem prozessornahen Cache (Cache-Level 1 bis 3) zu platzieren (sogenanntes Pre-Fetching). SanssouciDB unterstützt die darauf optimierten Speicher- und Caching-Strategien. Ausserdem: In kolumnen- respektive spaltenbasierten Datenbanken hängen die für die Analyse relevanten Daten seriell, also direkt hintereinander im Cache (Beispiel: Umsatzspalte) und können dadurch sehr schnell abgearbeitet werden. Optimal: hybride In-Memory-Datenbanken
Caching-Optimierungsstrategien sind nicht immer und in jedem Fall erfolgreich. Generell gilt es, Fehlzugriffe des Prozessors auf seine Level-1- und Level-2-Caches (und den gemeinsamen Level-3-Cache) möglichst stark zu reduzieren. Ansonsten müssen die fehlenden Daten aus prozessorfernen Speichern, wo sie quasi "irrtümlich" lagern, herangeschafft werden, was wieder Zeit kostet. Die Erfolgsquote ist stark abhängig vom jeweiligen Anwendungsfall. Herkömmliche, zeilenbasierte RDBMS glänzen bei transaktionalen Abfragen (Beispiele: Auftrags- oder Kundenstamm-Datensatz aufrufen). Kolumnenorientierte In-Memory-DBs schneiden hier nicht so gut ab, sondern spielen ihre Stärken bei analytischen Aufgaben aus (Beispiel: Kolummen Umsatz und Verkäufer aggregieren). Auf dem analytischen Auge sind wiederum die üblichen RDBMS eher blind. Plattner und sein Team schlagen daher hybride Datenbanken vor, die beide Speicherstrategien miteinander kombinieren und für beide Anwendungstypen gute Ergebnisse liefern. Hybride Datenbanken für gemischte Workloads, also transaktionale und analytische Abfragen, könnten laut Plattner die durchschnittliche Performance des Systems um bis zu 400 Prozent verbessern, wenn man sie mit ausschliesslich zeilenorientierten oder ausschliesslich kolumnenorientierten Datenbanksystemen vergleicht. (Literatur: Hasso Plattner, Alexander Zeier: In-Memory Data Management. An Inflection Point for Enterprise Applications, Springer: ab März 2011)