Was passiert, wenn ich eine Beispiel-Plattform nehme und mir überlege, wie ich sie mit Microservices umsetzen würde? Die Ergebnisse zeige ich in diesem Erfahrungsbericht in zwei Teilen auf.
Dass es eine Webapplikation werden soll, ist für mich ohne definierbaren Grund implizit klar. Beim Hinterfragen dieser Annahme komme ich zum Schluss, dass es keine so grosse Rolle spielt, ob der Benutzer einen Browser oder einen nativen Client vor sich hat ? die Kommunikation ausgehend vom Gerät des Benutzers dürfte in einem ersten Schritt über die gleichen Protokolle laufen. Einen Web-Shop will ich nicht schon wieder bauen, darum entscheide ich mich für ein News-Portal. Es gibt drei Benutzergruppen: Autoren, Leser und Administratoren.
Autoren können Beiträge schreiben. Beiträge werden zuerst als Entwurf gespeichert und dann vom Autor freigeschaltet.
Leser sehen die freigeschalteten Beiträge. Auf der Übersichtsseite werden die Überschriften sowie ein paar wenige Sätze pro Beitrag angezeigt, auf der Beitragsseite sieht der Leser den ganzen Text. Ausserdem werden auf der Beitragsseite Links zu ähnlichen Beiträgen (basierend auf den Tags) angezeigt.
Die Administratoren verwalten die Autoren.
Services
Nachdem ich nun weiss, was ich ?bauen? will frage ich mich: Wie verteile ich die Logik auf verschiedene Services? Die Aufteilung soll fachlich sein, das steht so mehr oder weniger in jeder Quelle. Ich schneide entlang der Benutzergruppen: Autoren editieren Beiträge, Leser lesen Beiträge. Die Administratoren lasse ich aussen vor, deren User-Interface greift auf eine Administrations-Schnittstelle des Autoren-Portals zu. Ich habe mich einfach an die Empfehlung gehalten und fachlich geschnitten. Wenn es die Empfehlung gibt, dann gibt es auch Alternativen, die gravierende Nachteile haben müssen. Eine solche Alternative habe ich in einem Umfeld erlebt, die mit Microservices wenig zu tun hatte: Eine N-Tier-Applikation war so auf Teams verteilt, dass jedes Team ein Tier betreute. Das bedeutete, dass alle Teams in jede noch so kleine Änderung der Anforderungen involviert waren und ihre Releases koordinieren mussten. Für die News würde eine technische Aufteilung folgendes bedeuten:
Es gibt technische Services (und Teams) für die Persistenz, die Business-Logik und für die UIs.
Eine Änderung am Autoren-Portal führt zu Änderungen im Autoren-UI, in der Business-Logik und vermutlich in der Persistenz.
Die Teams, die die verschiedenen Services betreuen, müssen sich für die Umsetzung koordinieren. Ausserdem kann es sein, dass die Anpassung an der Persistenz oder Business-Logik dazu führt, dass auch das Leser-UI angepasst werden muss, obwohl da keine Änderungen sichtbar sein sollten.
Als Vergleich die gleiche Änderung mit fachlich aufgeteilten Services: So lange das Autoren-Portal in der Lage ist, dem Leser-Portal das gleiche Interface zur Verfügung zu stellen wie vor der Änderung, ist das Leser-Portal nicht betroffen. Ein einzelnes Team ist in der Lage, die Änderung ohne Koordination mit anderen Teams umzusetzen. Übrigens habe ich ganz nebenbei auch noch eine Eigenschaft der Problemstellung ausgenutzt: Es gibt ein paar wenige Autoren und beliebig viele Leser. Damit, dass ich den beiden Benutzer-Gruppen getrennte Portale zur Verfügung stelle, trenne ich automatisch die (seltenen) Schreib-Transaktionen von den (häufigen) Lese-Transaktionen. Das vereinfacht die Skalierung, weil ich die lesenden Transaktionen auf Kopien der Daten auslagern kann, ohne dass ich mich um die Problematik von verteilten Updates kümmern muss.
Wo sind die Daten?
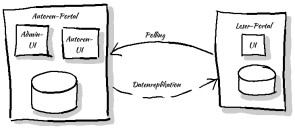
Die Empfehlung ist klar: Jeder Service ist für seine eigenen Daten verantwortlich, es gibt keine zentrale Datenbank. In meinem Beispiel gibt es aber nur Beiträge, und die werden vom Autoren-Portal verwaltet. Vielleicht ist mein Beispiel etwas gar klein geraten. Ein naiver Ansatz wäre, dass ein Service die benötigten Daten bei Bedarf vom zuständigen Service lädt. Damit das funktioniert, muss das Autoren-Portal aber so gross dimensioniert werden, dass es die Last des Leser-Portals tragen kann ? oder das Leser-Portal braucht einen grossen Cache. Stattdessen beschliesse ich, die Autoren und Beiträge im Leser-Portal zu replizieren. Diese Replikation benutze ich ausserdem dafür, dass die beiden Portale spezialisierte Domänen-Modelle benutzen können: Das Leser-Portal muss einfach alle Beiträge zu einem Tag finden können ? eine Suche, die im Autoren-Portal deutlich weniger wichtig ist. Dafür braucht das Autoren-Portal die zusätzliche Information, ob ein Beitrag schon publiziert ist. Das Ergebnis sind die folgenden Services:
So weit so gut ? aber wie kommen die Daten vom Autoren-Portal zum Leser-Portal? Synchron oder asynchron? Push oder Pull? Was für Protokolle? Formate? Was für Möglichkeiten habe ich überhaupt? Und welche davon kommen in Frage?
Push: Das Autoren-Portal könnte beim Publizieren (und bei jeder anschliessenden Änderung) das Leser-Portal benachrichtigen. Das kann entweder asynchron (über Messaging) oder über einen synchronen Aufruf sein ? und es ist beim synchronen Aufruf immer noch dem Leser-Portal überlassen, ob die Daten synchron oder asynchron verarbeitet werden.
Pull: Das Leser-Portal fragt regelmässig beim Autoren-Portal nach, ob es neue Beiträge gibt.
Das Leser-Portal hinkt hinterher, wird aber alle Daten früher oder später bekommen (eventual consistency).
Jetzt muss ich im Leser-Portal ?nur? noch dafür sorgen, dass der Atom-Feed regelmässig abgeholt wird und die Daten entsprechend eingepflegt werden. Natürlich muss ich dabei berücksichtigen, dass das Autoren-Portal auch Aktualisierungen von bereits bestehenden Einträgen publizieren kann. Es wird sich noch zeigen, dass diese Entscheidung für Polling mittelfristig überdacht werden muss. Warum, das lest ihr demnächst im 2. Teil.