Mit Machine Learning
13.12.2019, 13:15 Uhr
Neuer Schub für Open Data
Der Einsatz von Machine Learning in Kombination mit Open Data ebnet den Weg für zahlreiche Anwendungen. Doch die Nutzung der smarten Algorithmen ist nicht ganz ohne. Neue Konzepte zeigen, wie der Erfolg gelingt.

(Quelle: Franki Chamaki / Unsplash)
Auf der Website opendata.swiss können Anwender über 7000 öffentliche Datensätze, sogenannte Open Data, für Projekte nutzen. Die Informationen stammen von Behörden und Ämtern, etwa vom Bundesamt für Statistik oder dem Bundesamt für Gesundheit. Überdies bieten auch immer mehr Städte und Gemeinden ihre Daten für IT-Projekte an – offen und gratis. Daraus entstehen Anwendungen wie das Spital-Portal welches-spital.ch für Patienten auf der Suche nach dem für sie besten Krankenhaus oder Apps, die in Echtzeit freie Parkplätze anzeigen.
Open Data gewinnt an Bedeutung
Neben dem akademischen Umfeld setzt sich insbesondere auch im staatlichen Bereich immer mehr die Überzeugung durch, dass die öffentliche Hand ihre Daten Bürgerinnen und Bürgern sowie Akteuren aus der Wirtschaft zur Verfügung stellen sollte. Natürlich nur, soweit das sinnvoll ist und nicht durch andere Anforderungen wie das Urheberrecht und den Datenschutz verhindert werden.
Angetrieben wird der aktuelle Trend neben Akteuren wie opendata.swiss oder Events wie das Opendata-Forum auch durch die Schweizerische Bundesverwaltung, die aktiv Daten aufbereitet und anbietet: Der Linked Data Service (LINDAS) wurde 2015 vom Seco lanciert und wird seit 2017 vom Schweizerischen Bundesarchiv geführt. Es ist geplant, den Service auszubauen. Durch diesen können Anwender auf Daten verschiedener Eigentümer zugreifen, verarbeiten und dann dem allgemeinen Publikum, den Datenkonsumenten, zur Verfügung stellen.
Fünf Sterne für öffentliche Daten
Das Konzept von Open Data entstand 1957 im Rahmen des geophysikalischen Jahrs. Ziel war es, den Austausch und die Nutzung wissenschaftlicher Daten zu fördern. Einen entscheidenden Meilenstein setzte Tim Berners-Lee 2006 durch einen Vorschlag von Kriterien, die eine möglichst schrankenfreie Nutzung von Open Data sicherstellen sollten. Er verfeinerte die Klassifizierung zu seinem Fünf-Sterne-Entwicklungsschema für Open Data. Hierbei werden mit jedem zusätzlichen Stern die Kriterien der tieferen Level ergänzt:
★ Die Daten sind im Web verfügbar.
★ ★ Die Daten liegen in einem maschinenlesbaren, strukturierten Format vor.
★ ★ ★ Die Daten sind in einem nicht proprietären Format verfügbar.
★ ★ ★ ★ Es werden offene Standards des W3C verwendet wie RDF und SPARQL.
★ ★ ★ ★ ★ Die Daten werden mit anderen Linked Open Data verknüpft.
★ ★ Die Daten liegen in einem maschinenlesbaren, strukturierten Format vor.
★ ★ ★ Die Daten sind in einem nicht proprietären Format verfügbar.
★ ★ ★ ★ Es werden offene Standards des W3C verwendet wie RDF und SPARQL.
★ ★ ★ ★ ★ Die Daten werden mit anderen Linked Open Data verknüpft.
Sind diese fünf Kriterien erfüllt, spricht man von Linked Open Data. Das vierte Kriterium bedarf einiger Erläuterungen: Resource Definition Framework (RDF) erlaubt es, Metadaten in einer für Menschen und Maschinen lesbaren Form zu erstellen sowie semantische Technologien zu benutzen. Mit Ontologien können die Strukturen der Daten definiert werden. RDF und Ontologien erlauben Datenstrukturen, die komplexer sind als einfache Tabellen, nämlich sogenannte Wissensgraphen. Ebenso ermöglichen es Ontologien, Regeln zu definieren, mit denen aus expliziten Daten auch Fakten abgeleitet werden können.
Ein Beispiel: Wenn bei Personen eine Eltern-Kind-Beziehung definiert ist, kann mit einer Ontologie auch eine Grosseltern-Enkel-Beziehung bestimmt werden; ob Person A Enkel von Person B ist, kann dann abgeleitet werden, ohne dass dies explizit in den Daten gespeichert werden muss. SPARQL ist wiederum eine Abfragesprache für diese Datenstrukturen. Diese Ontologien bildeten auch das Rückgrat der Vision des semantischen Webs.
Neue Konzepte beflügeln Linked Open Data
Traditionell wurden zur Verarbeitung und Analyse von Linked Open Data semantische Technologien wie beispielsweise Ontologien benutzt. Die Mächtigkeit des Konzepts führte letztlich dazu, dass die algorithmische Komplexität schon bei kleinen Problemen nicht mehr handhabbar war. Bei grossen Datenmengen stösst die Technik daher an Grenzen, die häufig eine praktikable Umsetzung verhindern. Nach einer kurzen Hype-Phase folgte deshalb in der Szene Ernüchterung. Doch es deutet sich ein Comeback an.
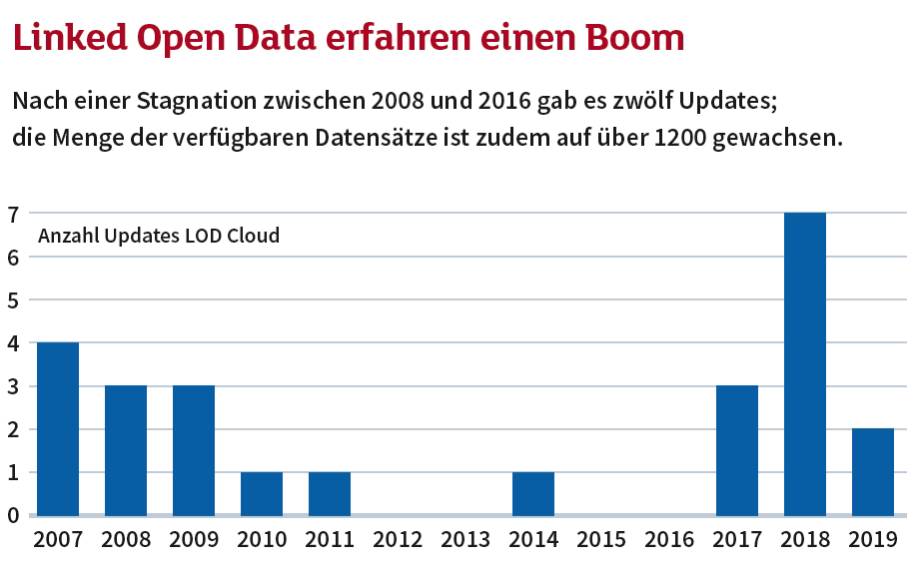
Quelle: FFHS / LOD Cloud Platform
Herausforderung für Machine Learning
Während klassische Verfahren der KI Algorithmen verwenden, die auf Formalismen der mathematischen Logik basieren, verwendet Machine Learning Modelle, die permanent und schnell mathematische Berechnungen auf Basis grosser Datenmengen durchführen. Beispiele sind Empfehlungen auf E-Commerce-Plattformen, selbstfahrende Autos oder Anwendungen der Betrugserkennung.
Es ist für viele Machine-Learning-Projekte allerdings eine grosse Herausforderung, Datensätze von guter Qualität und ausreichender Menge zu beschaffen. Neben dem Sammeln der Daten ist das Aufbereiten davon, das sogenannte Feature Engineering, in der Regel ein sehr zeitaufwendiger Teil eines Machine-Learning-Projekts. Denn Daten können aus unterschiedlichen Quellen stammen oder sie liegen in nicht standardisierten sowie unterschiedlichen Formaten vor. Genau hierin liegt das Potenzial einer Integration von Machine Learning und Linked Open Data. Denn bei Linked Open Data werden grosse Mengen an strukturierten und standardisierten Daten bereits angeboten. Die Datenstrukturen in der Welt von Linked Open Data sind jedoch häufig keine Tabellen, die sich ideal für das Machine Learning eignen, sondern komplexe Wissensgraphen. Eine Schwierigkeit, für die bereits an Lösungen gearbeitet wird.
Ansätze zur Verknüpfung von Machine Learning und Linked Open Data wurden von den Wissenschaftlern Peter Bloem und Victor de Vries 2014 mit der Idee entwickelt, dass RDF-Daten in einen Machine-Learning-Prozess direkt einbezogen werden müssten. In einer späteren Arbeit von Xander Wilcke, Peter Bloem und Victor de Vries 2017 wurden diese Ansätze konkretisiert: Statt einen Wissensgraphen in tabellarische Daten zu transformieren, sollten sie direkt als Input für Machine-Learning-Algorithmen verwendet werden. Aufbauend auf den klassischen Convolutional Neuronal Networks, wurden Graph Convolutional Networks entwickelt.
Es gibt bereits erste praktische Anwendungen des Konzepts. Eine solche ist das Empfehlungssystem PinSage für Pinterest. PinSage wurde in der Zusammenarbeit von Pinterest mit der Stanford University realisiert und übertrifft klassische Deep Learning Baselines (Ying et al 2018). Eine weitere Anwendung ist die Suite PoolParty der Semantic Web Company aus Wien. Das Unternehmen wurde 2018 im Gartner Hype Cycle for Artificial Intelligence Report als Musteranbieter erwähnt. PoolParty enthält einen sogenannten Semantic-Web-Klassifikator, dem Fachwissen in Form eines Wissensgraphen bereitgestellt wird.
Fazit
Gemäss Gartner sind Graphen einer der bedeutendsten Daten- und Analytik-Trends dieses Jahres. Ferner sei bis 2022 mit einem jährlichen Anstieg von 100 Prozent bei der Anwendung von Graph-Datenbanken zu rechnen. Im Gartner-Hype-Zyklus für aufkommende Technologien wird postuliert, dass Wissensgraphen und Graph-Analytik in fünf bis zehn Jahren das Plateau der Produktivität erreichen. Eine Kombination von Linked Open Data und Machine Learning wird hierbei eine wichtige Rolle spielen.
Die Autoren
Verfasst wurde dieser Beitrag von Urs-Martin Künzi und Martina Perani. Künzi ist Dozent am Laboratory for Web Science der Fernfachhochschule Schweiz. Perani ist an diesem als wissenschaftliche Mitarbeiterin tätig.




