23.11.2010, 06:00 Uhr
Das mitwachsende Datenmanagement
Wächst der Kundenstamm schneller als geplant, freut sich die Geschäftsleitung - und die IT hat ein Problem. Das Elektrizitätswerk Zürich bändigt die Datenflut mithilfe einer Open-Source-Lösung.
Business Development Manager bei Talend, Geschäftsführer von Public Footprint Sie erinnern sich: Mit Zustimmung der Zürcher Bevölkerung wurde dem Elektrizitätswerk Zürich (ewz) vor zwei Jahren ein Rahmenkredit für den Bau und Betrieb eines Breitbandnetzes auf Glasfaserbasis zur Modernisierung der Kommunikationsinfrastruktur bewilligt. Heute erreicht der Geschäftsbereich ewz Telecom mit ewz.zürinet 16000 Haushalte. Zwar standen zunächst der technische Aufbau des Glasfasernetzwerkes im Vordergrund. Die IT-Unterstützung der Geschäftsprozesse, beispielsweise für Abrechnungen oder den Service, sollten erst im nächsten Schritt im Fokus stehen. Der wurde dann allerdings schneller nötig als gedacht. «Wir haben unsere geplanten Zuwachsraten klar übertroffen und müssen schneller neue Anschlüsse bereitstellen als geplant», erklärt Cyril Zenger, als OSS/ BSS Engineer verantwortlich für Operation und Billing Support bei der ewz Telecom. Mit der Zahl der Kunden ist auch das Volumen der Stammdaten, zu denen neben den kundenbezogenen Daten alle Netzdaten gehören, gewachsen. Das, so Zenger, «hatte zur Folge, dass Prozesse und Anwendungen nur eingeschränkt auf benötigte Stammdaten zugreifen konnten». Um diese Lücke zu schliessen, begann man 2009 mit dem Aufbau eines zentralen Stammdaten-Hubs, der mittels einer zentralen Datenintegrationslösung befüllt werden sollte.
Zweifache Herausforderung
Bis Mitte 2010 verfügte die ewz über eine Point-to-Point-Architektur, bei der Daten in verschiedenen Systemen und diversen Rechnersystemen lagerten und jedes System beziehungsweise jede Anwendung bei Bedarf darauf zugriff. In dieser sternförmigen Architektur war zwar ein Datenaustausch zwischen allen Knoten möglich, aber ab einer gewissen Komplexität nicht mehr effizient. Das Fehlen gemeinsamer Protokolle, proprietärer Schnittstellen, ein geringer Automatisierungsgrad, mangelhafte Datenqualität und die Zahl der Schnittstellen machten vor allem die Verwaltung und Wartung schwierig. Im Vordergrund standen dabei zwei Herausforderungen: Aus der Historie gewachsen, weil alles schnell gehen musste, lagen viele Daten in Excel-Files vor. Einfach zu erstellen, aber sehr komplex zu warten. Bei der Bearbeitung und vor allem beim hin- und herschieben traten Fehler, Dubletten und Dateninkonsistenzen auf. Auch die Umwandlung ins CSV-Format und der sich anschliessende Transfer in die MySQL- Datenbank bereitete Kopfzerbrechen. Die Erstellung der notwendigen Pearl- und Java-Skripte kostet viel zu viel Zeit. Innerhalb der Excel-Umgebung gab es letztlich auch keine echte Datenqualität oder gar Nachvollziehbarkeit der Transaktionen. Die zweite Problematik lag im Reporting. Um in einer solchen Umgebung einen Report zu ziehen, müssen erst einmal die Quellen identifiziert und dann die Daten eingesammelt und aufbereitet werden - ein aufwendiger und vor allem langsamer Prozess.
Ziel: Effektive Datenstruktur

Datenmodellierung per Drag&Drop
Im Sommer 2010 begann das Team um Cyril Zenger mit dem Aufbau der Architektur des Stammdaten-Hubs. Als Erstes wurde das konzeptionelle Datenmodell in ein logisches überführt. Darauf folgte die Erstellung der Talend-Jobs mithilfe des integrierten, grafischen Modellierungswerkzeugs, mit dem auch komplexe ETL-Prozesse (Extraktion, Transformation, Laden) per Drag&Drop erstellt werden können.
Knackpunkte im Projekt
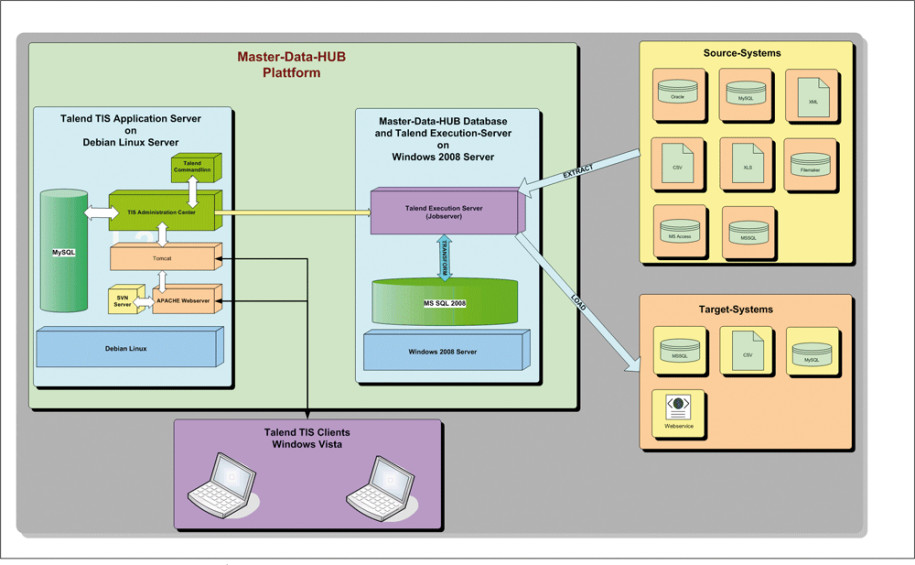
Der Umwandlungsprozess
Vor der Transformation werden die Daten aus Performance-Gründen zuerst in einen Offline-Data-Store geladen. Neben Oracle, MySQL und FileMaker mussten dabei auch Dateitypen wie Excel, CSV und XML berücksichtigt werden. Dabei handelt es sich vorwiegend um Kunden- und Netzdaten mit Informationen rund um die Anschlüsse und das gesamte Glasfasernetzwerk. Alle diese Angaben werden zur Steigerung der Datenqualität auf Fehler und Dubletten überprüft, bevor sie dann umgewandelt und Anwendungen wie Abrechnungs-systemen, Kommissionierung, Kundenverwaltung, Netzdokumentationssystemen oder SAP intern und extern zur Verfügung gestellt werden. Das Scheduling, also die zeit- und ereignisabhängige Planung und Steuerung der ETL-Prozesse, erfolgt mit dem in Talend integrierten «Admin-Center».
Datennetz auf Wachstumskurs
Insgesamt liegen in den Datenquellen rund 1,5 Millionen Stammdatensätze, die jede Nacht auf den zentralen Hub gezogen werden. In der bisherigen Point-to-Point-Umgebung wurde der Transfer halbautomatisch und relativ langsam mit diversen, eigen entwickelten Middleware-Anwendungen durchgeführt. Jetzt kann das gesamte Datenvolumen innerhalb von 45 Minuten bewegt werden. Künftig werden zu diesen internen auch externe Datenquellen von Partnern, Kunden und vor allem von anderen Stadtwerken, die das System von ewz nutzen wollen, hinzukommen. Aus diesem Grund hat man bei der Entwicklung von Anfang an auch die Mandantenfähigkeit des Systems im Blick gehabt. Die Installation wird in den kommenden Jahren weiter wachsen, mittelfristig soll der Stammdaten-Hub auch als Grundlage für ein Datamart und Datawarehouse genutzt werden, um Business-Intelligence-Aspekte wie Analysen und Berichte zu realisieren. Hinzu kommt, dass Ende 2009 die Swisscom und ewz beschlossen haben, den Ausbau des Glasfasernetzes in Zürich gemeinsam weiter voranzutreiben. Bis Ende 2017 wird man rund 430 Millionen Franken investieren, um über 200000 Haushalte und Unternehmen mit Glasfaseranschlüssen erreichen zu können.
Martin Lange, Thomas Schumacher




