Für KMU senken Cloud-Services die Einstiegshürde für Big Data erheblich. Allerdings hilft Big Data nur dann weiter, wenn man weiss, wonach man sucht.
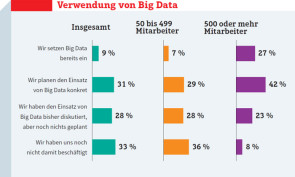
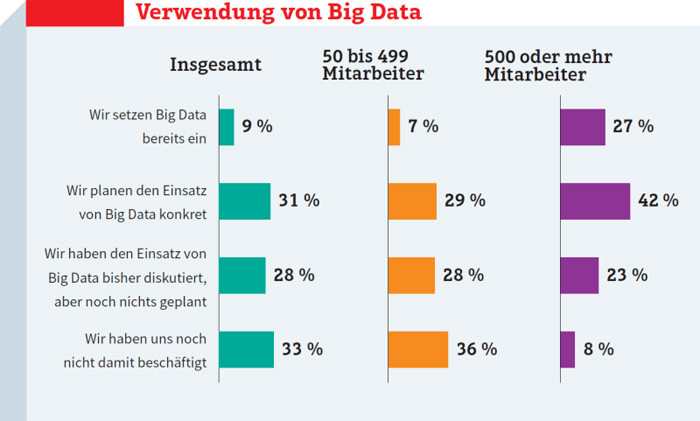
Viele kleine und mittelständische Unternehmen schreckt das «Big» in Big Data noch immer. Während laut einer Umfrage des Branchenverbands Bitkom 27 Prozent der Befragten aus Unternehmen mit 500 und mehr Mitarbeitern angaben, bereits Big-Data-Lösungen zu nutzen, waren es bei Mittelständlern mit 50 bis 499 Mitarbeitern nur 7 Prozent. Dabei steigen gerade im Mittelstand die Datenmengen stetig an – sogar schneller als in grösseren Unternehmen: In der Bitkom-Umfrage gaben 92 Prozent der befragten KMU an, ihr Datenvolumen sei von 2012 auf 2013 gestiegen, bei grösseren Unternehmen waren es «nur» 82 Prozent. Die Mittelständler verzeichneten ein durchschnittliches Datenwachstum von 22 Prozent, bei Unternehmen mit 500 und mehr Mitarbeitern waren es zwei Prozentpunkte weniger.
Diese Datenmengen bergen Informationsschätze, die noch allzu oft ungenutzt bleiben. Nach Angaben des Analystenhauses Forrester Research werten Unternehmen nur 12 Prozent der vorhandenen Daten aus. «Viele Unternehmen sind immer noch der Meinung, sie könnten das Thema Big Data aussitzen», sagt Hans Wieser, Business Lead Data Platform bei Microsoft Deutschland. Ein Fehler, davon ist Wieser überzeugt: «Es wird ganz schwierig werden, sich zu halten - oder gar Marktführer zu bleiben, wenn man die Möglichkeiten ignoriert, die Big Data bietet.» Lesen Sie auf der nächsten Seite: «Was Unternehmen den Einstieg in Big Data erschwert»
Was Unternehmen den Einstieg in Big Data erschwert
Neben den prinzipiellen Vorbehalten gegen die neue, noch vor Kurzem als mehr oder weniger esoterisch geltende Technik sind es vor allem vier Dinge, die den kleinen und mittelständischen Unternehmen den Einstieg in Big Data erschweren.
Die Datenflut: Das Datenaufkommen in KMU steigt kontinuierlich. Allein die Aufbewahrung, Sicherung und Verwaltung dieser Informationsmengen binden enorm viel IT-Personal und -Budget. In der Menge und der Vielfalt der Daten sieht Bob Plumridge, Chief Technology Officer EMEA von Hitachi Data Systems (HDS), die grösste Herausforderung: «Meist wissen Unternehmen einfach nicht, wo sie anfangen sollen.» Fehlendes Fachpersonal: Big-Data-Spezialisten, oft auch «Data Scientists» genannt, sind rar und - wie alles, was selten ist - teuer. «Viele Unternehmen können sich keine eigenen Data Scientists leisten, um das Maximum an Informationen aus den vorhandenen Daten herauszuholen», sagt Akash Mishra, der als Consultant Developer bei ThoughtWorks Unternehmen in Big-Data-Projekten berät. Das bestätigt die Bitkom-Studie. Ihr zufolge beklagen 65 Prozent der befragten Unternehmen einen Mangel an Big-Data-Spezialisten. Rechtliche Vorgaben: Unternehmen, die Daten erfassen, verarbeiten oder an Dienstleister übergeben, müssen zahlreiche Vorschriften und Regelungen beachten. Oft sind die gesetzlichen Vorgaben nicht mehr zeitgemäss, sagt Hans Wieser von Microsoft: «Die Rahmenbedingungen, die der Gesetzgeber vorgibt, stammen aus einer Zeit, als die Daten noch in Aktenschränken im Firmenkeller lagen.» Rund ein Fünftel der Unternehmen hat schon einmal aus rechtlichen Gründen auf eine Datenanalyse verzichtet, knapp jedes zweite hält den Datenschutz für ein Hemmnis beim Einsatz von Big-Data-Lösungen, so die Ergebnisse der Bitkom-Umfrage. Die Kosten: «Der Aufbau eines eigenen Server-Clusters für Big-Data-Analysen ist mit hohen Investitionen verbunden», sagt Consultant Mishra. Darüber hinaus fehle den IT-Verantwortlichen in kleinen und mittelständischen Unternehmen oft die Zeit und das Know-how, um beispielsweise einen Hadoop-Cluster aufzubauen und zu betreiben. «Big-Data-Analytics-Plattformen können je nach Anforderung eine sehr hohe Investition erfordern», warnt auch Gerhard Haberstroh, Marketing Big Data, HP Enterprise Services bei HP Deutschland. Lesen Sie auf der nächsten Seite: «Die wesentlichen Vorteile der Cloud im KMU»
Die wesentlichen Vorteile der Cloud im KMU
Ob Big Data als Service helfen kann, die skizzierten Probleme zu lösen, darüber sind sich die Experten uneins. «Big Data aus der Cloud hilft nicht bei der Lösung der eigentlichen Probleme», sagt Marco Schmid, Country Manager DACH beim Cloud-Provider Rackspace. Akash Mishra von ThoughtWorks ist anderer Ansicht: «Gerade kleine und mittelständische Unternehmen profitieren enorm von der Verlagerung in die Cloud.» Vor allem für Testsysteme oder Prototypen lohne sich der Aufwand einer eigenen Infrastruktur gar nicht: «In der Cloud lässt sich in kürzester Zeit ein Cluster aufsetzen und die Idee ausprobieren.» «Wenn es nicht funktioniert, kann man den Cluster genauso schnell wieder auflösen.» Dieses oft «Try often, Fail fast» genannte Prinzip, auf dem viele Big-Data-Projekte basieren, spricht gegen eine Installation im eigenen Rechenzentrum. Das findet auch Andreas Hufenstuhl, Head of Big Data & Analytics Central & Eastern Europe bei CSC: «In jedem Business Case können andere Datenvolumen, andere Datenformate, andere technische Verfahren oder andere Produkte aus dem Hadoop-Umfeld erforderlich sein. Diese Flexibilität kann in einer festen Big-Data-Umgebung kaum realisiert werden - oder es werden teure Überkapazitäten aufgebaut.»
Neben solchen Testszenarien profitieren vor allem zyklische Analysen von der Cloud, sagt John Kreisa, VP International Marketing bei Hortonworks: «Immer, wenn man schnell oder periodisch grosse Kapazitäten für Big-Data-Analysen braucht, profitiert man am stärksten vom Cloud-Modell.» IT-Experte Mishra nennt noch einen weiteren Grund, der für Big Data aus der Cloud spricht: «Frameworks wie Apache Spark verändern sich sehr dynamisch, es kommen ständig neue Funktionen und Verbesserungen hinzu. Wer diese Systeme selbst installiert, muss ständig Upgrades einspielen, die er zuvor auch noch auf ihre Kompatibilität testen muss.» Grosse Cloud-Provider böten dagegen immer die neuesten Versionen, ohne dass der Kunde etwas dazu tun müsse. Für Jens Bussmann, Cloud Platform Lead DACH & CEE bei Google, gibt es grundsätzlich kein Anwendungsszenario, das nicht besser in der Cloud aufgehoben wäre: «Die Cloud ist sowohl aus Kosten-, Leistungs-, Schnelligkeits- sowie auch aus Flexibilitätsgründen die bei Weitem beste Möglichkeit für Big-Data-Analysen.» Die offensichtlichen Vorteile von Big Data aus der Cloud werden in den kommenden Jahren für eine verstärkte Nachfrage sorgen. Der Gesamtmarkt für Big-Data-Technologien und -Services soll nach Prognosen des Marktforschungsunternehmens IDC bis 2018 jährlich um rund 26 Prozent wachsen und ein Volumen von rund 41,5 Milliarden Dollar erreichen. Cloud-Angebote legen dabei überproportional zu. So sagen die Analysten von Research and Markets allein für Hadoop as a Service bis 2019 ein durchschnittliches jährliches Wachstum von fast 85 Prozent voraus. Lesen Sie auf der nächsten Seite: «Die gröbsten Nachteile der Cloud»
Die gröbsten Nachteile der Cloud
Eine Verarbeitung in der Cloud ist vor allem dann wenig sinnvoll, wenn bereits grosse Datenmengen im Unternehmen vorliegen beziehungsweise direkt am Standort regelmässig anfallen. «Oft sind die Datenmengen riesig und wenn diese vor der Analyse in die Cloud geladen werden sollen, kann das nicht nur viel Zeit, sondern auch Geld kosten», sagt Hortonworks-VP Kreisa. Vor einer Entscheidung für oder gegen Big Data aus der Cloud sollte deshalb genau geprüft werden, wo die Daten anfallen und wie sie in die Analysesysteme gelangen sollen.
Genauso viele Gedanken wie um die Menge der Daten sollte man sich um deren Sensibilität machen. Nicht nur bei Kundendaten und geistigem Eigentum müsse man vorsichtig sein, sagt Andreas Hufenstuhl von CSC: «Auch Produktionsdaten oder Produktionsverfahren können (...) nicht einfach ungeschützt an einen Cloud-Provider übergeben werden.» In Branchen mit besonderen Reglementierungen wie bei Finanzdienstleistungen oder im Gesundheitswesen ist die Frage «Cloud oder nicht?» besonders genau zu prüfen. Big-Data-Services können ausserdem teuer werden, wenn sich das Nutzungsverhalten ändert, warnt Akash Mishra von ThoughtWorks. Entschliesst sich beispielsweise ein E-Commerce-Unternehmen aus Wettbewerbsgründen, eine Preiskalkulation auf einem Big-Data-Cluster in der Cloud nicht mehr einmal täglich, sondern stattdessen alle fünf Minuten durchzuführen, kann es den Cluster zwischendurch nicht mehr abschalten. «Das kann in der Cloud deutlich teurer werden, als wenn die Server im eigenen Rechenzentrum stünden», sagt Mishra. Wenn Unternehmen stark wachsen, kann es einen Punkt geben, an dem die Verarbeitung der Daten im eigenen Haus wirtschaftlicher wäre als die Auslagerung in die Cloud. «Dann ist die Datenmenge aber meist schon so gross, dass eine Migration ein hohes Risiko darstellt», so Mishra weiter. HP-Manager Haberstroh sieht in Big Data as a Service darüber hinaus eine Gefahr für die interne IT-Organisation: «Mit der Begründung, dass die IT-Abteilung für die Umsetzung der IT-Anwendungsfälle zu unflexibel ist oder auch zu wenig qualifiziertes Personal bereitstellen kann, nehmen die Fachabteilungen die Umsetzung zusammen mit Service-Providern selbst in die Hand.» Haberstroh rät der internen IT, sich selbst als Service-Provider für Big Data gegenüber den Fachabteilungen zu positionieren: «Die IT agiert damit als Service-Broker und bleibt in der Verantwortung.» Lesen Sie auf der nächsten Seite: «Der Aufbau von Big Data as a Service»
Der Aufbau von Big Data as a Service
Wie im Cloud-Modell üblich, lässt sich Big Data als Service auf verschiedenen Ebenen der zugrunde liegenden Infrastruktur realisieren.
Ein Unternehmen kann beispielsweise im IaaS-Modell (Infrastructure as a Service) Speicher des Cloud-Providers für die Datenhaltung und die Rechenleistung nutzen. Dabei spielt vor allem der genannte Vorteil der Flexibilität eine Rolle. Die Implementierung des Framework-Clusters, die Datenmodellierung und die Datenanalyse liegen komplett in der Hand des Kunden – weshalb dieser erhebliches Know-how benötigt. Auf der zweiten Ebene nutzt der Kunde Big Data als Platform as a Service (PaaS). Der Provider stellt Frameworks wie Hadoop, Spark oder Storm sowie Datenbanken wie Hive, HBase oder MongoDB zur Verfügung. Der Kunde muss sich nicht um die Einrichtung und den Betrieb des Systems kümmern, sondern kann sich auf die Modellierung der Fragestellung und die Analyse konzentrieren. Auch auf dieser Stufe ist allerdings noch erhebliches Know-how nötig, um aus der enormen Vielfalt an Werkzeugen das richtige für die eigenen Bedürfnisse auszuwählen. Schliesslich lassen sich praktisch fertige Big-Data-Analysen als Software as a Service (SaaS) mieten. Algorithmen, Skripte und Queries sind bereits so aufeinander abgestimmt, dass der Kunde ohne vertiefte Kenntnisse Reports und Grafiken auf Basis seiner Daten erstellen kann. Big-Data-Services sind meist sehr branchenspezifisch und vergleichsweise unflexibel. Dafür kommen Anwender damit sehr schnell zu Ergebnissen.
Lösungen aus der Cloud:
! TABELLE !
Lesen Sie auf der nächsten Seite: «Big Data bei Amazon und Google»
Big Data bei Amazon und Google
Rechenleistung und Speicher für Big Data nach dem IaaS-Modell bieten viele Cloud-Provider. Der bekannteste dürfte Amazon mit seinen Web Services (AWS) sein. Eine Hadoop-Instanz lässt sich auf Knoten der Elastic Compute Cloud (EC2) einrichten, zur Speicherung der Initialdaten nutzt man sinnvollerweise Amazon S3, da der Datentransfer zwischen S3 und EC2 kostenlos ist. Dort legt man auch die Ergebnisse ab, bevor der Cluster heruntergefahren wird. Temporäre Daten hält man dagegen besser im Hadoop Distributed File System (HDFS) vor.
Hadoop lässt sich manuell auf EC2 installieren, was allerdings sehr viel Erfahrung voraussetzt. Eine Anleitung dazu findet sich im Apache Wiki. Wer es einfacher haben will, kann Amazons eigenen Big-Data-Service Elastic MapReduce nutzen (EMR). Die dort verfügbaren AMIs (Amazon Machine Image) enthalten bereits ein bootfähiges Linux-Betriebssystem, Hadoop und weitere Software, die zum Betrieb des Clusters notwendig ist. Das aktuelle AMI Version 3.8.0 unterstützt neben Hadoop auch Hive, Hue, Pig, Hbase, Impala, Mahout und Spark. Big-Data-Spezialisten wie Cloudera, Hortonworks und der kürzlich von HDS übernommene Business-Intelligence-Spezialist Pentaho bieten ihre Distributionen ebenfalls auf EC2 an. So lässt sich mit Hilfe von Cloudera Director und einer Schnellstartvor lage von AWS der Cloudera Enterprise Data Hub (EDH) auf zwölf Cluster-Knoten nach Angaben von Amazon in nur 30 Minuten aufsetzen. Hortonworks Data Platform (HDP) ist mittels Apache Ambari ebenfalls recht schnell und einfach auf EC2 implementiert. Die Pentaho-Plattform nutzt neben EC2 das Amazon-eigene Data Warehouse Redshift und kann EMR oder andere gehostete Hadoop-Distributionen integrieren.
Big-Data-Services bei Google
Google bietet eine ganze Reihe von Big-Data-Services an, teils auf Basis von Open-Source-Lösungen, teils eigenständige Entwicklungen wie BigQuery oder Dataflow. Mit Click-to-deploy Hadoop on Google Compute Engine verspricht der Anbieter eine Installation des Big-Data-Frameworks in wenigen Minuten. Alles, was man nach Angaben des Providers dazu benötigt, sind ein Google Cloud Storage Bucket und ein paar Angaben zur Konfiguration. Optional lässt sich noch das Cloud SDK installieren, um per Kommandozeile auf die Hadoop-Instanzen zugreifen zu können. Weitere Big-Data-Lösungen liegen fertig vor und lassen sich einfach installieren, so etwa Cassandra, Elasticsearch, MongoDB und Redis. Gleich drei Varianten hat der Provider für die Echtzeitanalyse im Angebot: Die erste ist eine Kombination aus dem Cluster-Manager Kubernetes, der In-Memory-Datenbank Redis und dem Abfragesystem BigQuery. In der zweiten Variante können Anwender Kubernetes und BigQuery mit Pub/Sub verknüpfen, einem Real-Time-Messaging-System. Für Logging-Zwecke lässt sich BigQuery auch noch mit dem Open-Source-Datensammler Fluentd kombinieren. Im vergangenen Jahr hat Google ausserdem den Big-Data-Service Cloud Dataflow gestartet, der sich derzeit noch im Beta-Stadium befindet. Google Cloud Dataflow erlaubt die Analyse grosser Datenmengen sowohl im Batch- als auch im Streaming-Modus nahezu in Echtzeit. Der Code ist für beide Methoden gleich, die Entscheidung trifft der Entwickler durch die Wahl der Datenquelle. Die Programmierung ist sehr einfach. Für die Analyse muss ein Entwickler die logischen Schritte nur in eine Sequenz einfacher Befehle übersetzen. Um zum Beispiel ein Zeitfenster für eine Streaming-Analyse zu definieren, genügt eine Zeile Code. Google verspricht ausserdem eine Skalierbarkeit bis in den Exabyte-Bereich und eine nahtlose Integration in andere Systeme. «Dataflow ist als Pipelining- und Management-Technologie für ein grosses Spektrum an Big Data-Diensten und -Applikationen verfügbar», sagt Jens Bussmann von Google. Lesen Sie auf der nächsten Seite: «Big Data bei Microsoft und anderen Providern»
Big Data bei Microsoft und anderen Providern
In der Microsoft-Cloud Azure gibt es ebenfalls diverse Big-Data-Analyse-Angebote. HDInsight etwa stellt einen Hadoop-Cluster zur Verfügung. Dieser soll sich ebenfalls in wenigen Minuten aufsetzen, bis in den Petabyte-Bereich skalieren und mit lokal installierten Hadoop-Instanzen verknüpfen lassen. Mit Machine Learning lassen sich erfahrungsbasierte Analysealgorithmen über einen Webservice definieren und ausführen, wie sie zum Beispiel zur Entwicklung von Vorhersagemodellen (Predictive Analytics) verwendet werden. Echtzeitanalysen kann der Anwender mit Stream Analytics durchführen und zur Datenerfassung mit Event Hubs kombinieren, einer Plattform, die Log-Daten schnell in grossen Mengen aufzeichnen kann, wie sie etwa auf Webseiten, mobilen Endgeräten oder in Industrieanlagen anfallen. Microsoft bietet die Möglichkeit, die Services einen Monat lang kostenlos zu testen. Start-ups können Machine Learning sogar drei Jahre gratis nutzen. Unterstützung bei der Einrichtung bietet neben den zahlreichen Microsoft-Partnern auch die Virtual Academy des Anbieters. Erst vor Kurzem hat Microsoft die Cortana Analytics Suite angekündigt, die im Herbst 2015 auf den Markt kommen soll. Sie verbindet die bestehenden Big-Data-Cloud-Angebote mit einer Perceptive Intelligence genannten Auswahl an Werkzeugen zur intelligenten Erfassung und Verarbeitung von Daten. Dazu zählen Microsofts Siri-Alternative Cortana sowie Tools zur Sprach- und Gesichtserkennung und zur Analyse von Texten oder Bildern.
Big-Data-Services anderer Provider
Big-Data-Services gibt es von zahlreichen weiteren Unternehmen und in verschiedenen Ausprägungen. Einige treten als Big-Data-Spezialist und Cloud-Provider in einem auf, andere nutzen die Infrastruktur von Amazon, Google, Microsoft oder anderen Plattformanbietern, um ihre Hadoop-Distributionen oder Analyse-Tools hosten zu lassen. Alles aus einer Hand offeriert beispielsweise IBM mit Spark as a Service auf seiner App-Development-Plattform Bluemix. InfoSphere BigInsights, dasDB, Hadoop und weitere Big-Data-Services sind dort ebenfalls verfügbar. SAP bietet seine In-Memory-Datenbank HANA auch als Platform as a Service in der eigenen Cloud an, sie läuft aber auch in den Clouds von Amazon, IBM und HP. Aus HPs HP Helion Cloud sind auch Cassandra und andere Big-Data-Services zu beziehen. Wie HP Helion basieren auch die Clouds von Mirantis und Red Hat auf der Open-Source-Infrastruktur OpenStack. Dort kümmert sich die Entwicklergemeinde in einem Projekt namens Sahara um die Integration von Hadoop als Service.
Fazit
Keine Frage: Cloud-Services senken die Einstiegshürde für Big Data erheblich. Nutzungsabhängige Tarife ohne Vertragsbindung oder Fixkosten halten die Investitionen in erste Big-Data-Projekte in überschaubaren Grenzen. Oft sind Teststellungen sogar gratis zu haben. Zahlreiche Cloud-Provider bieten vorgefertigte Pakete für die häufigsten Anwendungsszenarien, sodass die Installation für erfahrene Entwickler oft in wenigen Minuten erledigt ist. Die Cloud löst allerdings nicht das Kernproblem von Big Data. Viele Unternehmen vergessen nämlich über der Begeisterung, endlich ihre Datenschätze heben und analysieren zu können, völlig, sich zu fragen, was genau sie eigentlich wissen wollen. Wer einfach nur Petabytes von Daten mit Abfragen bombardiert, wird am Ende mit Dutzenden von Korrelationen dastehen – und nicht klüger sein als zuvor. «Durch die reine Korrelation von Daten wird noch kein Kausalzusammenhang bestätigt», erinnert Google-Manager Bussmann zu Recht an eine simple Wahrheit, die allzu oft ignoriert wird.