Alibaba Cloud
15.08.2023, 13:07 Uhr
Vortrainierte LLMs für die Open-Source-Community
Alibaba Cloud veröffentlicht seine 7-Milliarden-Parameter-LLM-Modelle (Qwen-7B, Qwen-7B-Chat) als Open Source.
(Quelle: alibabacloud.com)
Im April 2023 hat Alibaba Cloud sein neuestes generatives KI-Modell "Tongyi Qianwen" vorgestellt. Nun öffnet das Unternehmen den Quellcode von zwei Large Language Models (LLM), Qwen-7B und die Chat-optimierte Version Qwen-7B-Chat, mit denen Tongyi Qianwen trainiert wurde, für die Open-Source-Gemeinschaft.
In dem Bestreben, KI-Technologien zu demokratisieren, werden der Code, die Modellgewichte und die Dokumentation der Modelle für Akademiker, Forscher und kommerzielle Einrichtungen weltweit frei zugänglich sein. Für die kommerzielle Nutzung sollen die Modelle für Unternehmen mit weniger als 100 Millionen monatlich aktiven Nutzern kostenlos zur Verfügung stehen. Programme mit mehr Nutzern können eine Lizenz bei Alibaba Cloud beantragen.
Beide LLMs können laut Alibaba Cloud in Cloud- und On-Premises-Infrastrukturen eingesetzt werden. Dies ermöglicht den Anwendern eine Feinabstimmung der Modelle und das effektive und kosteneffiziente Erstellen eigener generativer KI-Fähigkeiten.
So charakterisiert Alibaba Cloud die beiden jetzt freigegebenen LLMs:
Qwen-7B wurde mit über 2 Billionen Token trainiert, darunter chinesische, englische und andere mehrsprachige Materialien, Code und Mathematik, die allgemeine und berufliche Bereiche abdecken. Seine Kontextlänge erreicht 8K. Beim Training wurde das Qwen-7B-Chat-Modell mit menschlichen Anweisungen abgeglichen. Sowohl das Qwen-7B- als auch das Qwen-7B-Chat-Modell können in Cloud- und On-Premises-Infrastrukturen eingesetzt werden. Dies ermöglicht den Anwendern eine Feinabstimmung der Modelle und die effektive und kosteneffiziente Erstellung eigener hochwertiger generativer Modelle.
Qwen-7B wurde mit über 2 Billionen Token trainiert, darunter chinesische, englische und andere mehrsprachige Materialien, Code und Mathematik, die allgemeine und berufliche Bereiche abdecken. Seine Kontextlänge erreicht 8K. Beim Training wurde das Qwen-7B-Chat-Modell mit menschlichen Anweisungen abgeglichen. Sowohl das Qwen-7B- als auch das Qwen-7B-Chat-Modell können in Cloud- und On-Premises-Infrastrukturen eingesetzt werden. Dies ermöglicht den Anwendern eine Feinabstimmung der Modelle und die effektive und kosteneffiziente Erstellung eigener hochwertiger generativer Modelle.
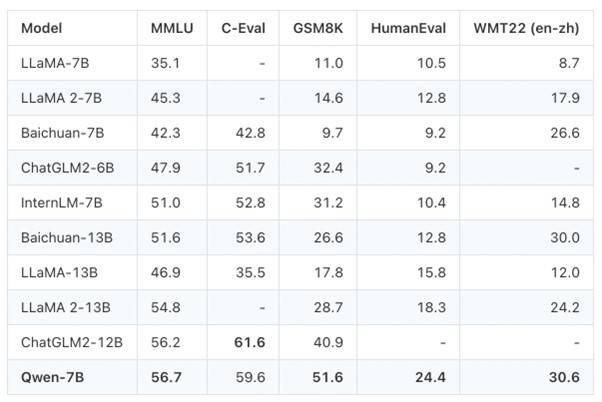
Das vortrainierte Qwen-7B-Modell zeichnete sich im Massive Multi-task Language Understanding (MMLU)-Benchmark aus und erreichte einen beachtlichen Wert von 56,7, womit es andere wichtige vortrainierte Open-Source-Modelle mit ähnlichem Umfang oder sogar einige grössere Modelle übertraf. Bei diesem Benchmark wird die Multitasking-Genauigkeit eines Textmodells bei 57 verschiedenen Aufgaben bewertet, die Bereiche wie elementare Mathematik, Informatik und Recht umfassen. Darüber hinaus erreichte Qwen-7B die höchste Punktzahl unter Modellen mit gleichwertigen Parametern in der Rangliste von C-Eval, einer umfassenden chinesischen Evaluierungssuite für grundlegende Modelle. Sie deckt 52 Fächer in vier grossen Fachbereichen ab, darunter Geisteswissenschaften, Sozialwissenschaften, MINT und andere. Darüber hinaus erreichte Qwen-7B herausragende Leistungen bei Benchmarks in den Bereichen Mathematik und Codegenerierung, wie GSM8K und HumanEval.
Weitere Informationen zu Qwen-7B und Qwen-7B-Chat finden Sie auf den Seiten von ModelScope, Hugging Face und GitHub.

Autor(in)
Bernhard
Lauer




