Früher waren Datenbanken mit mehr als einem Terabyte eine Ausnahme. Heute sind fünf Terabyte die Regel und 10 bis 200 Terabyte keine Seltenheit. Nur ein optimiertes Datenmanagement kann solche Mengen vernünftig speichern.
Der Autor ist Director SAP Solution Engineering bei NetApp Deutschland Oracle-, SharePoint- und SAP-Systeme haben eines gemeinsam: Jedes dieser Systeme produziert Unmengen von Daten. Allein mit dem Speichern ist es nicht mehr getan. Performance, Verfügbarkeit, Virtualisierung sowie Integration von Backup und Applikationen sind Aspekte, die bei der Optimierung ebenso berücksichtigt werden wollen. Performance je nach Workload Beim Storage hängt die Performance ganz klar vom Anwendungsprofil ab. Grob gesehen gibt es hier zwei Einflussfaktoren: sequenzieller Workload und Random-Workload. ERP-Anwendungen haben in der Regel ein I/O-Profil mit einem sehr hohen Random-Anteil, typischerweise 70 Prozent (bei einem Lese-/Schreib-verhältnis von 80 Prozent für Lesen und 20 Prozent für Schreiben). Der Grund: Sehr viele kleine Datensätze, die zum Beispiel beim Anlegen einer Bestellung oder Rechnung entstehen. Im Gegensatz dazu haben Datawarehouses ein Profil mit sehr hohem sequenziellem Anteil und hohem Schreibanteil. Datawarehouses werden sehr oft täglich mit neuen Daten aus verschiedensten Systemen geladen oder neu aufgebaut, was einen hohen Schreibanteil bedeutet. Bei Datawarehouse-Abfragen dagegen ist das Gegenteil der Fall: Hier sieht man meist komplette Lesevorgänge einer Tabelle, was normalerweise einem sequenziellen Zugriff entspricht. Diese unterschiedlichen I/O-Profile entscheiden über die Bemessung des Storage. Bei sequenziellen Zugriffen sind weniger Festplatten notwendig als bei Random-Zugriffen, da die Platte im sequenziellen Zugriff die Schreib-/Leseköpfe nicht positionieren muss. Richtschnur ist die Menge der MB/s, die eine Disk liefert. Die Performance bei sequenziellem Zugriff lässt sich auch sehr einfach per Cache im Storage-System erhöhen. Im Gegensatz dazu hängt die Random-I/O-Performance wiederum von der Anzahl der Festplatten ab. Da eine SAS-Disk heute bei ca. 150–200 IOs pro Disk liegt, kommt man bei 10 Festplatten auf 1500–2000 IOPS (Input/Output Operations per Second). Noch ist es schwierig, eine Performance-Steigerung durch einen Cache für Random-Zugriff zu erreichen. Storage-Hersteller arbeiten aber mit intelligenten und flashbasierten grossen Caches in den Storage-Controllern oder mit SSD-Festplatten daran. Die beste Kenngrösse für die Dimensionierung der Storage-Performance sind die IOPS und die Grösse der Datenbestände. Ohne diese Werte sollte der Speicherhersteller des Kunden die bestehende Installation vermessen oder nach Applikationsangaben dimensionieren, obwohl Letzterem eine gewisse Ungenauigkeit anhaftet. Für die Dimensionierung gelten aber noch andere Gesichtspunkte wie Speicherzugriffsprotokolle oder Netzwerktopologie, sprich SAN oder NAS, Ethernet oder Fibre Channel. Langfristig geht der Trend zu einer einheitlichen Ethernet-Topologie mit allen Protokollen wie Fibre Channel over Ethernet (FCOE), iSCSI, NFS, CIFS etc. Im Datenbankumfeld kommen unter den Unix-Plattformen NFS, iSCSI und Fibre Channel zum Einsatz. Im Windows-Umfeld kommen dagegen mit der Ausnahme von SharePoint und Oracle nur blockbasierende Protokolle wie FC, FCoE oder iSCSI zum Einsatz. Oracle bietet ab Version 11 die Möglichkeit einer eigenen High-Performance-Implementierung von NFS (dNFS). Damit ist NFS Storage direkt aus der Applikation und ohne Performance-Overhead im Betriebssystem ansprechbar – unter Unix ebenso wie unter Windows. Der Vorteil besteht in der Kombination von hoch performantem Zugriff mit der Einfachheit des NAS-Datenmanagement direkt aus der Applikation. Bei SharePoint und Microsoft gibt es die Möglichkeit, Files direkt im CIFS (Filesystem) abzulegen, während die Referenzinformationen in der Microsoft-SQL-Server-Datenbank gespeichert werden. Allgemein geht der Trend zu Unified Storage, das heisst, das Storage-System enthält sämtliche Protokolle. Speicherressourcen und -protokolle lassen sich dynamisch der jeweiligen Applikation anhand ihrer Anforderungen zuordnen. Die Entscheidung für ein Protokoll hängt heute allerdings nicht mehr von der Performance ab, da diese bei SAN und NAS nahezu identisch ist. Bei der Storage-Netzwerk-Fabric geht der Trend zu Ethernet. Allerdings werden hier keine Fibre-Channel-Fabrics abgelöst, sondern vielmehr im ersten Schritt erweitert, um den Fibre-Channel-Investitionen vieler Unternehmen Rechnung zu tragen. Knackpunkt Verfügbarkeit Ein wesentlicher Punkt sind die Verfügbarkeits-SLAs aus Applikationssicht: Wie sieht die Recovery Point Objective (RPO), also der maximal tolerierbare Datenverlust, aus? Null Stunden oder eine Stunde? Welcher Wert kommt der Recovery Time Objective (RTO) zu, also wie lange darf eine Applikation ausfallen? Beide Parameter bestimmen die Eckdaten der Lösung: Bei RPO grösser als null ist eine asynchrone Spiegelung denkbar, was deutlich die Kosten reduziert. Bei einer RTO von null reicht synchrone Spiegelung alleine nicht. Jetzt sind Business-Continuity-Lösungen im Storage gefragt, die zusätzlich zur synchronen Spiegelung transparente Failover auf den Disaster-Recovery-Standort ausführen. Eine solche Lösung sollte möglichst ohne Scripting auskommen, da Skripte fehleranfällig sind und auch menschliches Versagen eine Rolle spielt: So wird bei Änderungen auf der Produktionsseite gerne vergessen, auch auf der Disaster-Seite die Skripte entsprechend anzupassen, was oft erst im Katastrophenfall auffällt. Beispiel Storage-Virtualisierung Ein weiteres spannendes Thema für Applikationen ist die Storage-Virtualisierung, hier speziell virtuelle Kopien. Ein Beispiel aus dem SAP-Umfeld: Viele Kunden betreiben nicht nur ein Produktionssystem, sondern auch Test- und Schulungssysteme, die Kopien des Produktivsystems sind. Für jedes Terabyte (TB) Produktivdaten bedeutet das auch fünf TB Testdaten und damit fünf TB Storage-Kapazität. Bezieht man zusätzlich die ganze SAP-Landschaft mit Business Intelligence, Customer Relationship etc. ein, so erhöht sich die Anzahl um ein Vielfaches. Moderne Speichersysteme bieten hier die Möglichkeit virtueller Kopien (Klone). Man erzeugt lediglich eine virtuelle Kopie der Produktionsdaten – ohne diese tatsächlich zu kopieren. Für zwei Systeme eines Produktionssystems mit zwei TB Daten plus einem Testsystem mit zwei TB Daten werden dann nur zwei TB Speicherkapzität anstatt vier TB benötigt. Die Kopien oder Klone sind innerhalb weniger Sekunden erzeugt. Sie benötigen nur Speicherplatz für Daten, die sich ändern. Damit reduziert sich der Speicherplatz erheblich, was sich auch auf die Verbrauchswerte von Strom und Kühlungsbedarf auswirkt. In vielen Projekten wird die virtuelle Cloning-Technologie eingesetzt, um mehr Schulungssysteme zu erzeugen und die Einführung von SAP-Modulen zu beschleunigen. SAP ist dabei nur ein Beispiel, die Technologie lässt sich für alle Applikationen einsetzen. Wichtig bei allen diesen Technologien: Sie sind nur einsetzbar unter der Voraussetzung, dass die Snapshots und Klone keinen Performance-Einfluss auf die Produktionsdaten haben. Datenbanken sichern - vom Tape zur Disk Aufgrund der stetig grösser werdenden Datenmengen und der infolgedessen immer längeren Backup- und Recovery-Laufzeiten setzen die Rechenzentren im Applikations- und Datenbankumfeld vermehrt auf Backup-to-Disk und verwenden Bandspeicher nur noch als Archivmedien. Die Snapshot-Technologie dient in diesem Fall als Backup bzw. Recovery Point. Zusätzlich werden die Snapshots auf einen anderen Speicher mit hochkapazitiven SATA-Disks ausgelagert und häufig auch noch auf Band archiviert. Das Snapshot-Backup-Verfahren verändert die Serverlast und das Backup-Fenster. Die folgenden Abbildungen zeigen am Beispiel Oracle die Unterschiede zum traditionellen Backup.
Abbildung 1: Das traditionelle Backup einer zwei Terabyte grossen Datenbank dauert mit traditionellem Tape ca. vier Stunden. Damit ist der Server vier Stunden im Backup-Modus und läuft mit erhöhter Backuplast. Aufgrund der Serverbelastung ist mehr als ein Backup pro Tag nicht machbar.
Abbildung 2: Bei Restore und Recovery kommt zusätzlich zur Dauer der Rücksicherung vom Band die Zeit für einen «Roll Forward» hinzu. Für die Behebung eines Datenbankfehlers, der um 10:00 Uhr auftrat, setzt das Restore aus dem Backup von 20:00 am Vortag an und erfordert in unserem Beispiel einen Roll Forward von sechseinhalb Stunden.
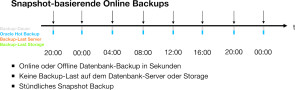
Abbildung 3: Beim Snapshot-Backup dauert das Backup nur Sekunden und produziert auch keine Last auf dem Server. Folglich kann die Anzahl der Backups erhöht werden, beispielsweise sind jetzt Backupzyklen im Vier-Stunden-Rhythmus möglich.
Abbildung 4: Bei einem Snapshot-Backup würde man den Snapshot von 8:00 morgens verwenden, damit ist das Recovery in zwei Stunden fertig anstatt in sechs. Die Zeit kann durch die Anzahl Snapshots noch weiter verringert werden. Die Vorteile derartiger Backup-Verfahren liegen klar auf der Hand: kürzere Backup-Fenster, kürzere Recovery-Dauer.