Object Storage ermöglicht es, riesige Mengen unstrukturierter Daten zu verwalten. Unternehmen bietet die Technik zudem die Möglichkeit, bei Bedarf eine Hybrid-Cloud-Umgebung zu schaffen.
Alle Unternehmen kämpfen derzeit mit dem Problem, rapide ansteigende Datenmengen bewältigen zu müssen. Sie sammeln immer mehr Informationen und nutzen dafür die unterschiedlichsten Datenquellen. Multimedia-Dateien, aber auch Office-Dokumente stellen schon jetzt das Konzept einer verteilten Speicherung mit Hilfe von NAS-Speichern (Network Attached Storage) oder SAN-Arrays (Storage Attached Networks) vor grosse Herausforderungen. Den Marktforschern von Gartner zufolge wächst das Volumen unstrukturierter Daten jährlich um 40 bis 60 Prozent.
Verschärft wird die Situation, weil die neueren Mobility-, Web- und Big-Data-Analytics-Anwendungen alle mit grösseren Datensets arbeiten als die traditionellen Applikationen. Die bislang vorherrschenden hierarchischen, dateisystemgetriebenen Storage-Architekturen sind jedoch kaum dafür geeignet, diese Flut oft unstrukturierter Daten zu verwalten. Sie setzen häufig sehr umfangreiche Dateisysteme mit tief verzweigten Hierarchien von Verzeichnissen und Unterverzeichnissen ein und sind deshalb sehr schwerfällig, wenn es darum geht, aus einem Set von Milliarden Dateien auf eine ganz bestimmte zuzugreifen. Darüber hinaus gibt es für die meisten im Einsatz befindlichen Dateisysteme Einschränkungen, was die Anzahl der zu verwaltenden Dateien angeht – und damit letztlich auch für die Datenmenge, die insgesamt gespeichert werden kann. Abhilfe versprechen die Hersteller objektbasierter Speicherlösungen. Sie sollen eine praktisch grenzenlose Skalierbarkeit, eine hohe Performance und einen schnellen Zugriff bieten. Nächste Seite: Die Datei als Objekt - Metadaten als Schlüssel
Die Datei als Objekt - Metadaten als Schlüssel
Herkömmliche Storage-Lösungen eignen sich optimal für die Verwaltung von Transaktionsdaten, die sich permanent ändern. Unstrukturierte Daten indes, die sich selten oder überhaupt nicht ändern, sind besser in hoch skalierbaren, kostengünstigen Objektspeichern aufgehoben. Sie lassen sich als zusätzliche Speicherschicht für Big Data, Archive und auch für Backups verwenden.
Public-Cloud-Dienste wie Amazon S3, Google, Facebook oder Microsoft Azure nutzen das Konzept der Objektspeicherung ebenfalls. Object Storage bezeichnet einen Ansatz, bei dem die Daten als Objekte in einem flachen Adressraum, einem Speicher-Pool ohne Unterverzeichnisse, gespeichert werden. Objektspeicher bestehen aus kostengünstigen Clustern aus x86-basierten Knoten, wobei jeder Ressourcen für Berechnungen (Compute) und Speichern (Storage) vorhält. Bei Object Storage handelt es sich um eine Scale-out-Architektur, das heisst, der Speicherplatz lässt sich theoretisch durch das Hinzufügen weiterer Knoten unendlich erweitern. Jedes Objekt stellt eine Einheit für sich dar, die die eigentlichen Daten, deren Metadaten und einen eindeutigen Identifier umfasst. Die Daten werden in Containern flexibler Grösse statt in Blöcken fester Grösse vorgehalten. Der Zugriff auf die Objekte erfolgt über eine global eindeutige Objekt-ID, ähnlich wie eine URL auf eine Datei im Web verweist. Administratoren profitieren von der Tatsache, dass Daten als Objekte und nicht mehr als Dateien oder Blöcke dargestellt werden, denn dies enthebt sie der Aufgabe, logische Volumes zu erstellen und zu managen oder RAID-Level aufzusetzen. Eine wichtige Rolle für die Effizienz der Objektspeicher spielen die Metadaten. Sie lagern, unter anderem aus Performance-Gründen, getrennt von den eigentlichen Daten. So lassen sie sich schneller durchsuchen.
Metadaten als Schlüssel
Die Metadaten liefern zusätzliche Kontextinformationen zu den Daten. Während sie sich in dateibasierten Speichersystemen auf Dateiattribute beschränken, können sie in objektbasierten Systemen mit weiteren Informationen angereichert werden. Je nach Implementierung, Anwendung oder System lassen sich in die Metadaten Informationen zu Datenschutzanforderungen, Autorisierung und Zugangskontrolle sowie zu anderen Compliance-Forderungen wie Aufbewahrungszeiten miteinbeziehen. Das steigert die Datenqualität und die Quality of Service (QoS) und verbessert das Sicherheitsmanagement. Die angereicherten Metadaten erlauben es ausserdem, Regeln und Policies für das Replizieren der Objekte und das Archivieren in Storage Tiers vorzugeben. Die Speicherung kann dann zum Beispiel nicht nur nach dem Dateinamen, sondern auch nach Funktion und Kontext erfolgen. Nächste Seite: Architekturschichten der Objektspeicher-Software
Architekturschichten der Objektspeicher-Software
Die Objektspeicher-Software besteht aus lose gekoppelten Services und ist hardwareunabhängig:
Ein Präsentations-Layer verwaltet die Schnittstellen zu den Clients über HTTP-Protokolle via REST und meist zusätzlich über traditionelle Dateisystemprotokolle.
Ein Metadatenmanagement-Layer bestimmt, wo die Objekte gespeichert werden, wie sie auf Speicherknoten verteilt und wie sie geschützt werden.
Der Storage-Layer bildet die Schnittstelle zu den Knoten.
Redundanz und Hochverfügbarkeit sollen über die Verteilung desselben Objekts auf mehrere Knoten gewährleistet werden. Erzeugt ein Nutzer ein neues Objekt, so wird dies je nach Policy auf einen oder mehrere Knoten kopiert. Die Knoten können im selben Rechenzentrum sein oder in den meisten Implementierungen auch geografisch verteilt. Um Probleme beim Handling des gleichzeitigen Zugriffs mehrerer Nutzer auf eine Datei zu umgehen, lassen sich Objekte nicht updaten, es werden vielmehr jeweils neue Versionen mit eigenen IDs erzeugt – ein Vorteil für verteilte Speicher und verteilten Zugriff. Um die Verfügbarkeit und Integrität der Daten zu erhöhen, ersetzen die meisten Anbieter von Objektspeichern das traditionelle RAID-Verfahren durch eine Variante der sogenannten Erasure-Coding-Methode. Dabei werden die Daten in Fragmente aufgeteilt, mit redundanten Datenteilen erweitert und codiert und auf mehreren Knoten verteilt gespeichert. Für die Rekonstruktion beschädigter Dateien werden diese Informationen dann aus anderen Speicherorten wieder zusammengesetzt. Auf diese Weise lässt sich Overhead und damit Zeit bei der Datenrekonstruktion sparen. Gerade bei grossen Datenmengen oder bei fehlertoleranten Anwendungen hat sich diese Methode als sehr nützlich erwiesen. Nächste Seite: Die Entwicklung des Objektspeichermarkts
Die Entwicklung des Objektspeichermarkts
Als die ersten Objektspeicher-Plattformen auf den Markt kamen, wurden sie vor allem als Archive genutzt. Darüber hinaus gab es zunächst nur wenige Einsatzszenarien, weil die meisten Anwendungen auf herkömmliche Speicher ausgerichtet waren. Die Objektspeicher boten dafür nur proprietäre Zugriffsmechanismen.
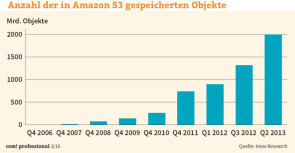
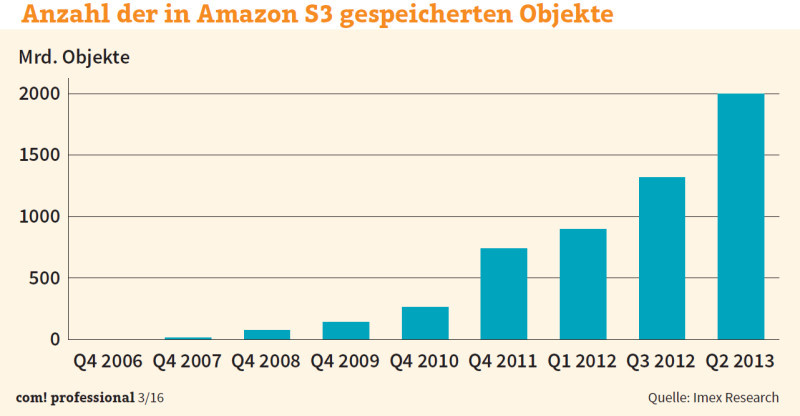
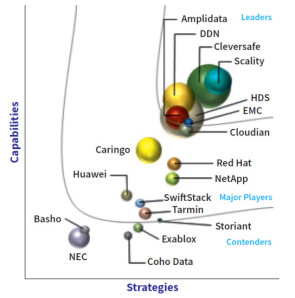
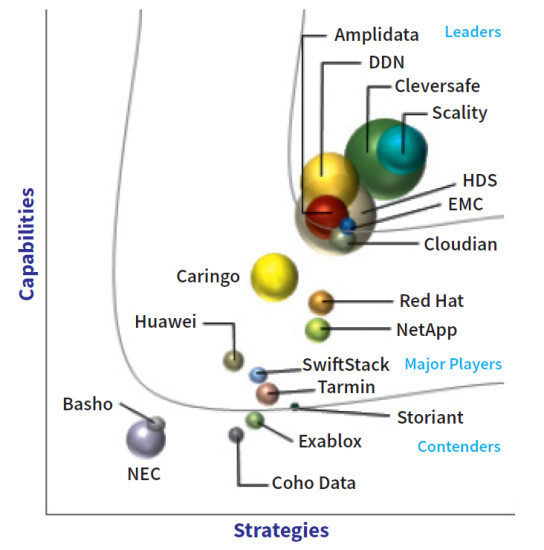
Diese Situation änderte sich grundlegend mit dem Siegeszug der Cloud. Immer mehr Web- und Mobility-Anwendungen waren darauf ausgelegt, ihre Daten in Objektspeichern abzulegen. Objektspeicher stellen die Basisschicht für die Datenspeicherung in vielen weit verbreiteten Cloud-Diensten dar, etwa beim Public-Cloud-Marktführer Amazon Web Services S3, aber auch bei Microsoft Azure. Mittlerweile liefern alle erfolgreichen Objektspeicher eine Programmierschnittstelle für den De-facto-Standard Amazon S3. Breite Unterstützung geniesst aber auch die Object-Storage-Lösung OpenStack Swift. Das OpenStack-Projekt entwickelt eine freie Architektur für Cloud-Computing und wird unter anderem von Dell, HP, IBM, Intel, Red Hat und Suse Linux unterstützt. Für die typischen Einsatzszenarien in Cloud-Umgebungen oder geografisch verteilten Umgebungen eignet sich zudem der Zugriff über Internetprotokolle wie HTTP und eine RESTful-API besser als die traditionellen, auf ein Rechenzentrum beschränkten Zugänge über TCP-Ports. Zu den Vorzügen heutiger Object-Storage-Produkte zählt ausserdem, dass viele Implementierungen auch eine Datei- oder Block-Schnittstelle über Protokoll-Gateways anbieten. Die Marktforscher von IDC schätzen für das Jahr 2018 den Anteil der Objektspeicherlösungen am gesamten Storage-Markt auf 27 Prozent. In ihrer Marktanalyse «IDC MarketScape: Worldwide Object-Based Storage» von Ende 2014 benennen sie sieben Anbieter als Marktführer («Leader»). Diese sieben Object-Storage-Leader stellt com! professional näher vor – zunächst fünf auf Objektspeicher spezialisierte Anbieter – Cleversafe, Amplidata, Scality, DataDirect Networks und Cloudian –, dann die Generalisten EMC und Hitachi Data Systems. Nächste Seite: Die Spezialanbieter Cleversafe und Amplidata
Die Spezialanbieter Cleversafe und Amplidata
IDC sieht die Stärke von Cleversafe in dessen zehnjähriger Erfahrung mit Objektspeichern. Cleversafe kenne sich daher besonders gut mit den Anforderungen der Anwender aus, was man seinem Top-Produkt Dispersed Storage Network (dsNet) auch anmerke.
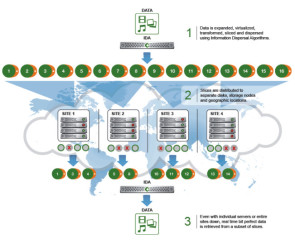
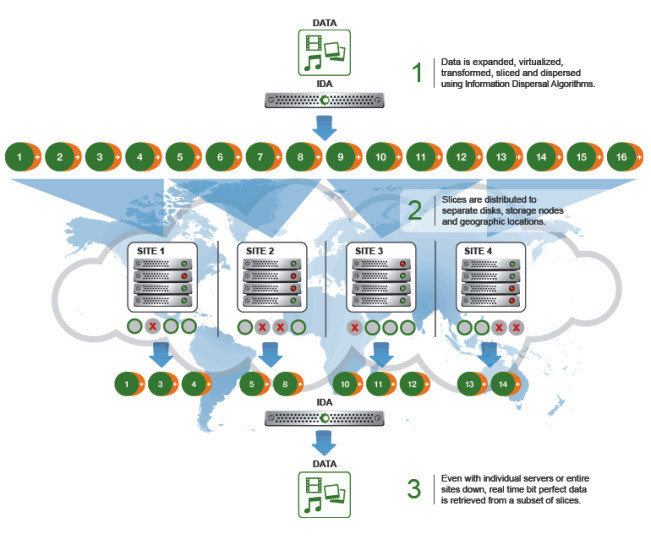
Das Cleversafe-Flaggschiff ist auf Private Clouds ausgerichtet. Es wird als Cluster in einer Kombination aus drei Arten von Knoten jeweils mit dem eigenen Betriebssystem ClevOS aufgesetzt. Die drei Knoten sind der sogenannte Manager, der sich um den Betrieb des Objekt-Repositories kümmert, die als Slicestors bezeichneten Speicherknoten und der Accesser, der die REST-Zugriffsschnittstelle zu den Anwendungen liefert. Die Knoten sind zu Pools zusammengefasst, wobei eine dsNet-Implementierung mehrere Pools haben kann. Daneben lassen sich mit dsNet logische Container (Vaults) einrichten, für die eine bestimmte Verfügbarkeit definiert wird und die besondere Datentransformations- und Zugriffskontroll-Möglichkeiten bieten. Mehrere Vaults können demselben Pool zugeordnet werden. Die Accessers sind für die Verteilung der Daten verantwortlich, die mit Hilfe eines patentierten Information-Dispersal-Algorithmus (IDA) in Einzelteile zerlegt und über die Knoten auch in geografisch verteilte Umgebungen übertragen werden. Der Algorithmus übernimmt zudem das Erasure Coding für den Schutz der Daten bei Ausfällen der Knoten. IDC hält Sicherheit und Zuverlässigkeit für die grössten Stärken von dsNet. So ist zum Beispiel SecureSlice integriert, eine Verschlüsselungstechnik, die ohne Key-Managementsystem auskommt. Die Daten werden verschlüsselt, bevor sie in Teile zerlegt und auf den Knoten abgelegt werden. Der Zugriff kann nur dann erfolgen, wenn die vom Information-Dispersal-Algorithmus vordefinierte Anzahl der Teile «eingesammelt» sind – das soll die Effizienz des Erasure Codings erhöhen. Für zusätzliche Sicherheit soll auch das Konzept sorgen, dass kein Knoten alle diese Teile enthält. Anwender können das gewünschte Fehlertoleranz-Level selbst im IDA konfigurieren. Der Datenintegrität sollen der mehrschichtige Integritäts-Check und Datenreparaturen im Hintergrund zugutekommen. Schnittstellen zu Amazon S3, dem hoch verfügbaren Dateisystem HDFS (Hadoop Distributed File System) sowie OpenStack Swift sind ebenfalls vorhanden, sodass Kunden ihre Private Clouds mit Public-Cloud-Anwendungen nutzen können. Cleversafe wurde kürzlich von IBM übernommen und soll in Big Blues Cloud-Geschäft integriert werden. Bislang war IBM im Objektspeichermarkt nicht vertreten.
Amplidata
Der kleinere Spezialanbieter Amplidata aus Belgien wurde vor ein paar Monaten von HGST, einer Tochter der Western Digital Corporation, gekauft. Amplidata bietet mit AmpliStor und Himalaya zwei Scale-out-Lösungen, die vor allem auf die fehlertolerante Verteilung und Speicherung von Daten über eine hohe Anzahl Platten ausgerichtet sind und dem Hersteller zufolge bis auf mehrere zehn Petabyte skalieren können. Ermöglichen soll diese Skalierbarkeit die selbst entwickelte Erasure-Encoding-Technik BitSpread. Diese Technik basiert auf einem RAIN Grid (Redundant Array of Inexpensive Nodes) und ist damit viel verlässlicher als RAID-Lösungen. Anwender können die Verfügbarkeitskonfiguration selbst bestimmen und in Policies festhalten. BitDynamics wiederum nimmt eine proaktive Selbstüberprüfung und -reparatur von Plattenfehlern vor. Als das Alleinstellungsmerkmal ihrer Software nennen die Belgier die Möglichkeit, unabhängig voneinander Namespace, Systemdurchsatz und Speicherkapazität zu skalieren. Nächste Seite: Scality, DataDirect Networks und Cloudian
Scality, DataDirect Networks und Cloudian
Scality, der Zweitplatzierte im IDC-Ranking, konzentriert sich mit seiner Software RING auf Umgebungen mit Datenvolumina im Petabyte-Bereich sowie auf Anwender, die über Commodity-Hardware Kosten sparen wollen. Dafür setzt Scality auf performante Cluster mit mindestens sechs Standard-Servern in einer sogenannten Shared-Nothing-Architektur. Diese Distributed-Computing-Architektur kann durch Hinzufügen einzelner Server unter einem einzigen globalen Namespace bis in den Petabyte-Bereich skalieren. In der mehrschichtigen RING-Architektur können die Zugriffsknoten unabhängig voneinander skalieren. Die Metadaten werden ebenfalls auf die Knoten verteilt, um keinen Flaschenhals durch ein zentrales Metadaten-Repository entstehen zu lassen. Upgrades und geplante oder ungeplante Systemwartungen lassen sich im laufenden Betrieb durchführen. Der Schutz der Daten wird entweder für kleinere Dateien durch Replizierung oder für grössere Dateien durch die selbst entwickelte Erasure-Coding-Technik ARC (Advanced Resilience Configuration) gewährleistet. Scality eröffnet über eine virtuelle Dateisystemschicht die Möglichkeit, sowohl Datei- als auch Objektdaten in demselben System vorzuhalten. Der Zugriff darauf erfolgt über traditionelle Dateischnittstellen wie NFS (Network File System), das SMB-Protokoll (Server Message Block) oder über REST-Schnittstellen wie CDMI (Cloud Data Management Interface), Amazon S3 und OpenStack Swift. Der Zugriff auf VM-Storage von VMware ist ebenfalls möglich. Auf diese Weise will Scality den Markt für seine Lösung möglichst umfassend ansprechen.
DataDirect Networks (DDN)
DDN gehört laut IDC neben Cleversafe und Hitachi Data Systems zu den drei Anbietern mit dem grössten Marktanteil. DDN will mit der Web-Object-Scaler-Plattform (WOS) Anwender wie Service-Provider erreichen, die Riesenmengen an unstrukturierten Daten verwalten müssen. Die Storage-Knoten bestehen dabei aus Viereinheiten-Servern mit jeweils 60 SATA-Platten. Die WOS-Plattform kann geografisch verteilt aufgesetzt werden und bietet für den Schutz der Daten mit Global Object Assure eine Erasure-Coding-Implementierung, die lokal oder auf mehrere Sites verteilt funktioniert. Zudem lässt sich der Schutz auch mit Hilfe einer Datenreplizierung sicherstellen. Ein S3-Gateway stellt die Verbindung zur Amazon-Cloud zur Verfügung. Ausserdem unterstützt WOS Umgebungen mit dem Cluster-Dateisystem GPFS (General Parallel File System) und die Protokollerweiterungen zum Common Internet File System (CIFS).
Cloudian
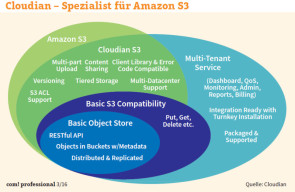
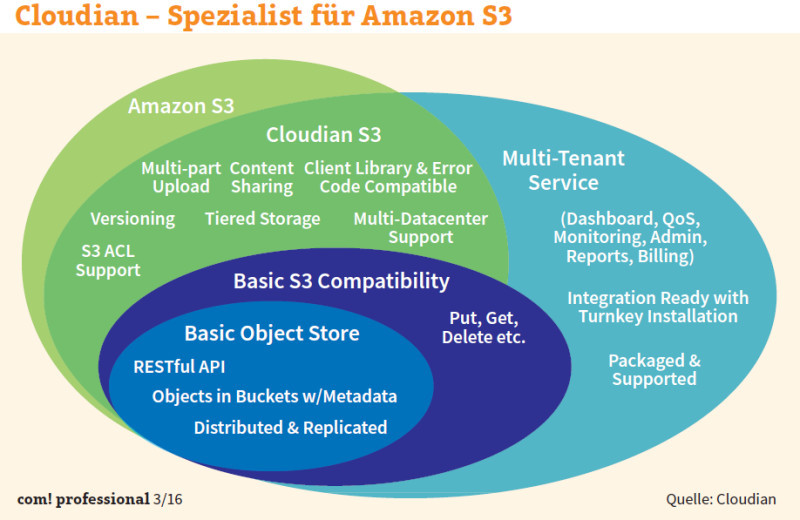
Zu den spezialisierten Newcomern im Bereich der Object-Storage-Leader gehört auch Cloudian. Seine für Hybrid Clouds geeignete Lösung Hyperstore setzt ebenfalls auf eine Ring-Architektur, die alle Knoten in einem einzigen globalen Namespace zusammenfasst. Der Anbieter wirbt für seinen Objektspeicher unter anderem mit Apache Cassandra, einem Repository für Metadaten. Dieses verteilte NoSQL-Datenbankverwaltungssystem ist auf hohe lineare Skalierbarkeit und niedrige Latency ausgelegt.
Unternehmensangaben zufolge kann das Datenbankverwaltungssystem die Indizes auf Hunderte von Knoten verteilen. Das Modul Hadoop Analytics soll innerhalb der Objekte eine schnelle Suche und Analyse der Daten ermöglichen. Und schliesslich bietet Cloudian laut eigenen Aussagen als einziger Hersteller eine vollständige Implementierung der Amazon-S3-Schnittstelle – inklusive Bereichen wie Versionierung, Multipart Uploading (Hochladen grosser Objekte in Teilen) und Replizierung von Objekten über verschiedene AWS-Regionen hinweg. Darüber hinaus hat der Anbieter die API durch Quality of Service und Monitoring erweitert. Die Summe dieser Funktionen soll Anwendern die Möglichkeit eröffnen, eigene S3-Clouds aufzusetzen. Darüber hinaus lassen sich die Daten aus dem Objektspeicher in Amazon S3 oder damit kompatible Clouds schieben (Tiering). Cloudian rechnet sich dank seiner S3-Implementierung erhebliche Wettbewerbsvorteile aus, denn es gibt mehr als 400 Anwendungen, die S3 nutzen können. Cloudian behauptet, mit einer TCO von einem Cent pro Gigabyte und Monat günstiger zu sein als Amazons Public-Cloud-Dienst. Nächste Seite: Die etablierten Allrounder EMC und HDS
Die etablierten Allrounder EMC und HDS
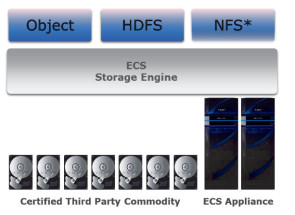
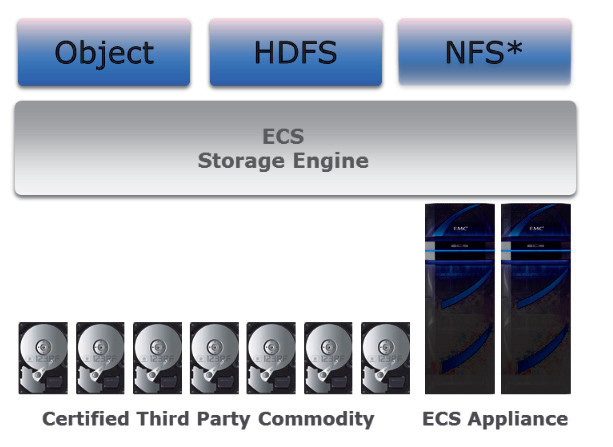
Auch die beiden etablierten Speicheranbieter EMC und HDS zählt IDC in seiner MarketScape-Analyse zu den Leadern. Beide vertreten einen breiten «Portfolio-Ansatz» mit mehreren Produkten, um Object-Storage-Fähigkeiten über mehrere eigene Plattformen hinweg liefern zu können. Mit Centera war EMC unter den Appliances der ersten Objektspeicher-Generation vertreten, die noch keine Cloud-Features hatten und nur fürs Rechenzentrum geeignet waren. Zudem verkauft EMC seit sieben Jahren das Objektspeicherprodukt Atmos, das laut EMC für Private Clouds geeignet ist und eine S3-Schnittstelle bietet. Seine neueste Lösung nennt EMC Elastic Cloud Storage (ECS). Auf sie ist die künftige Strategie des Unternehmens bezüglich Objektspeicher ausgerichtet. ECS wird als rein softwarebasierte Lösung oder als Appliance bereitgestellt. Der Cloud-Speicher soll dabei auf Standard-Hardware bis in den Exabyte-Bereich skalieren können.
EMC positioniert ECS auch als Alternative zu Public Clouds und spricht von einer um bis zu 28 Prozent niedrigeren TCO verglichen etwa mit den Public Clouds von Amazon oder Google. ECS unterstützt Amazon S3 und OpenStack Swift und stellt ergänzend das Protokoll Hadoop File System (HDFS) für schnelle Big-Data-Analytics-Anwendungen zu Verfügung. Zu der Funktionalität von ECS gehört eine automatische Ausfallsicherung, die den Zugang zu Containern und Objekten auch beim vorübergehenden Ausfall eines Standorts ermöglicht. Nach Wiederherstellung der Verbindung aller Zonen werden die Standorte automatisch synchronisiert. Der Objektspeicher speichert über einen Geo-Caching-Layer lokale Daten in einem verteilten Cache, um einen schnellen Zugriff auf Daten von allen Standorten aus zu gewährleisten.
Hitachi Data Systems
Hitachi liefert mit der Content Platform (HCP) eine Objektspeicherlösung, die durch die Module Data Ingestor (HDI) und HCP Anywhere ergänzt wird. HDI soll in einer Cloud- oder einer verteilten Umgebung eine Verbindung zum Kernrechenzentrum herstellen, ohne dass Anwendungen neu codiert oder die Interaktion von Benutzern mit Speicherressourcen verändert werden müssen. HDI fungiert als Caching-System und kümmert sich um Aufgaben wie Content-Freigabe und Basisverzeichnisse mit Roaming, Datensicherheit und -wiederherstellung. Es nutzt Erasure Coding über eine zusätzliche Speicherschicht in Form einer Hardware-Box, der die Daten über die Erasure-Coding-Softwareschicht zugeführt werden. HCP Anywhere wiederum ist eine On-Premise-Lösung für die sichere und zuverlässige Freigabe und Synchronisierung von Dateien in der Private Cloud. Schnittstellen zu Amazon S3 und Microsoft Azure sind ebenfalls vorhanden.
Fazit
Objektspeicher spielen ihre Vorteile für Unternehmen aus, die Riesenmengen an Daten zu verwalten haben und deren Top-Prioritäten dabei Skalierbarkeit und hohe Datenverfügbarkeit in einer flexiblen Infrastruktur bei einer möglichst niedrigen TCO darstellen. Sie bieten Unternehmen zudem die Möglichkeit, bei Bedarf eine Hybrid-Cloud-Umgebung zu schaffen, indem sie die Schnittstellen zu den öffentlichen Cloud-Speicherdiensten nutzen.