Die Big-Data-Software Spark hat einen neuen Geschwindigkeits-Weltrekord aufgestellt. Auf dem Daytona Gray Sort Challenge analysierte Spark 100 TByte in 23 Minuten. Die Apache-Open-Source-Software gibt's kostenlos zum Download.
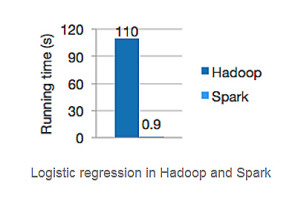
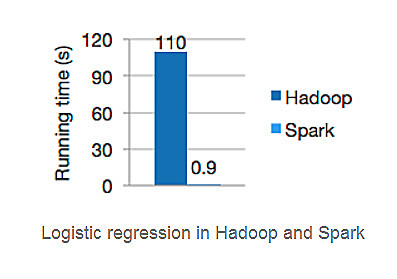
Hadoop hat Big-Data-Analytics durch Performance revolutioniert, aber benutzerfreundlich ist es nicht. In den letzten Jahren kamen daher Frameworks auf den Markt, die dieses Manko beheben sollten: Hortonworks und Cloudera sind zwei davon. Beide Frameworks unterstützen zum Beispiel SQL-Queries über unstrukturierte respektive semi-strukturierte Daten. In den letzten Wochen aber macht ein Framework von sich reden, das Hadoop in seiner ureigensten Domäne schlägt: Spark. Im Daytona Gray Sort Benchmark siegte Spark in der 100-TByte-Kategorie und stellten einen neuen Weltrekord auf. Der alte Weltrekord lag bei 72 Minuten, dabei kamen ein Hadoop-MapReduce-Cluster zum Einsatz, das aus 2100 Knoten bestand. Sparkunterbot den alten Rekord mit 23 Minutenmehr als deutlich, und benötigte dafür lediglich ein Zehntel der Hardware-Power.
"Es gibt einen starken Konsens in der Branche, dass Spark der Weg ist, den wir gehen müssen", sagt Curt Monash, Chef des IT-Analystenhauses Monash Research. "Im nächsten Jahr werden wir eine ganze Reihe von Hadoop-Use-Cases sehen, die weit über die Möglichkeiten von Hadoop hinausgehen", ergänzt Ali Ghodsi von Databricks. Spark ist eine sogenannte "Engine", um Daten zu analysieren, die über einem Cluster von Rechnern verteilt abgespeichert sind. Dadurch lassen sich Teilaufgaben parallel bearbeiten, was wiederum die Performance in die Höhe treibt. Nach dem gleichen Prinzip arbeitet auch Hadoop. Wie Hadoop kann auch Spark Datenmengen - auch unstrukturierte - analysieren, die zu gross sind, um in ein herkömmliches Data Warehouse oder in eine relationale Datenbank zu passen.
Spotify setzt auf Spark
Durch Machine-Learning-Algorithmen und Streaming Data geht Spark jedoch über Hadoop hinaus. Der Musikdienst Spotify setzt die Software ein, um seine Empfehlungslisten (Playlists) zu optimieren. Hadoop-Distributoren wie Cloudera, Hortonworks und MapR haben Spark in ihre Angebote integriert. 60 Enterprise-Kunden von Cloudera hätten die Engine bereits im Einsatz, schreibt IDG-News-Redaktor Joab Jackson. Spark startete 2008 als Software-Projekt an der Universität von Kalifornien (Berkeley). Unter den Fittichen der Apache Software Foundation bekommt das Projekt mehr Unterstützung als alle andere Apache-Software-Projekte. Zu den Firmen, die Beiträge leisten, gehören unter anderem Intel, Yahoo, Groupon, Alibaba und Mint. Das Spark-Framework (Download) läuft auf Hadoop, Apache Mesos, als Standalone-Anwendung oder in der Cloud (EC2). Unterstützt werden zurzeit die Programmiersprachen Java, Scala und Python. Die entwickelten Applikationen sollen 100 Mal schneller als Hadoop MapReduce laufen, wenn man den In-Mem-Cache von Spark einsetzt. Auf Disk beträgt der Performance-Vorteil 10x. (mit Material von IDG News Service)